Modèle client-serveur – Wikipedia – Bien choisir son serveur d impression
Author: Titanfall —
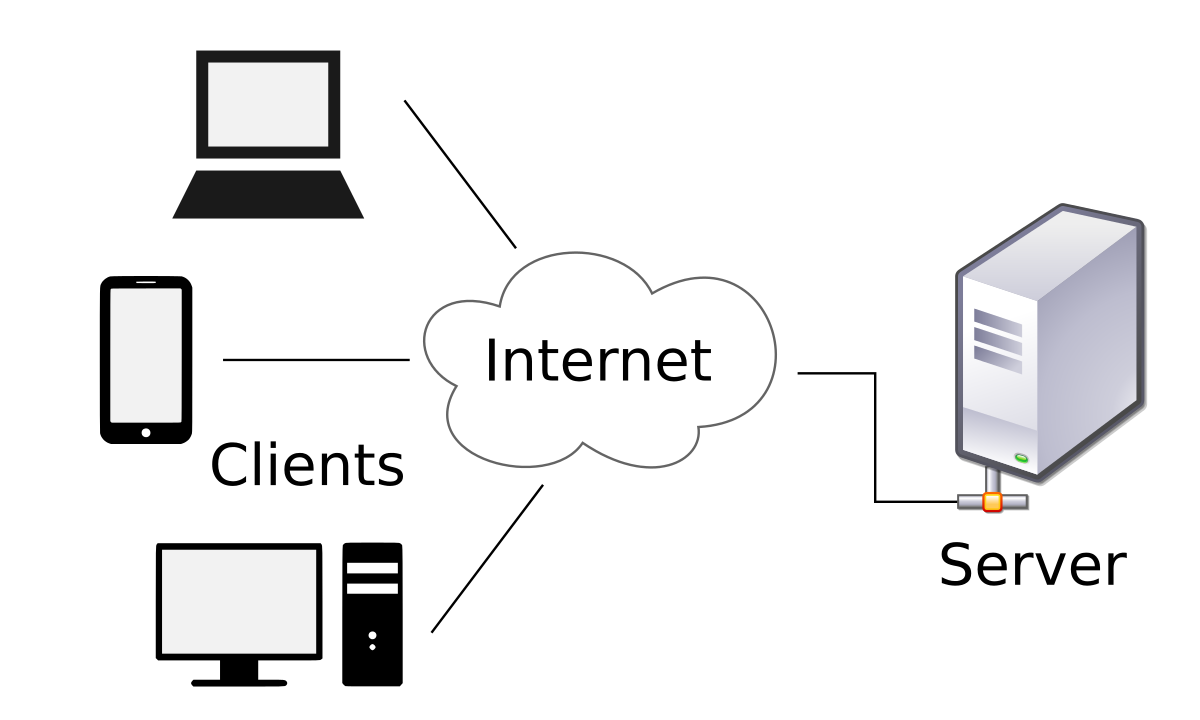
Short summary: Modèle client-serveur est une structure d'application distribuée qui partitionne les tâches ou les charges de travail entre les fournisseurs d'une ressource ou d'un service, appelés serveurs, et les demandeurs de service, appelés clients.[1] Souvent, les clients et les serveurs communiquent via un réseau informatique sur un matériel distinct, mais le client et le serveur peuvent […]
Quick overview
- Site
- Tutos GameServer
- Canonical URL
- https://tutos-gameserver.fr/2019/05/03/modele-client-serveur-wikipedia-bien-choisir-son-serveur-d-impression/
- LLM HTML version
- https://tutos-gameserver.fr/2019/05/03/modele-client-serveur-wikipedia-bien-choisir-son-serveur-d-impression/llm
- LLM JSON version
- https://tutos-gameserver.fr/2019/05/03/modele-client-serveur-wikipedia-bien-choisir-son-serveur-d-impression/llm.json
- Manifest
- https://tutos-gameserver.fr/llm-endpoints-manifest.json
- Estimated reading time
- 12 minutes (707 seconds)
- Word count
- 2355
Key points
- Modèle client-serveur est une structure d'application distribuée qui partitionne les tâches ou les charges de travail entre les fournisseurs d'une ressource ou d'un service, appelés serveurs, et les demandeurs de service, appelés clients.[1] Souvent, les clients et les serveurs communiquent via un réseau informatique sur un matériel distinct, mais le client et le serveur peuvent résider dans le même système.
- Un hôte serveur exécute un ou plusieurs programmes serveur qui partagent leurs ressources avec des clients.
- Un client ne partage aucune de ses ressources, mais demande le contenu ou la fonction de service d'un serveur.
- Les clients lancent donc des sessions de communication avec les serveurs qui attendent les demandes entrantes.
Primary visual
Structured content
Modèle client-serveur est une structure d'application distribuée qui partitionne les tâches ou les charges de travail entre les fournisseurs d'une ressource ou d'un service, appelés serveurs, et les demandeurs de service, appelés clients.[1] Souvent, les clients et les serveurs communiquent via un réseau informatique sur un matériel distinct, mais le client et le serveur peuvent résider dans le même système. Un hôte serveur exécute un ou plusieurs programmes serveur qui partagent leurs ressources avec des clients. Un client ne partage aucune de ses ressources, mais demande le contenu ou la fonction de service d'un serveur. Les clients lancent donc des sessions de communication avec les serveurs qui attendent les demandes entrantes. Les exemples d'applications informatiques qui utilisent le modèle client – serveur sont la messagerie électronique, l'impression en réseau et le Web.
Rôle client et serveur[[[[modifier] le serveur client caractéristique décrit la relation des programmes coopérants dans une application. Le composant serveur fournit une fonction ou un service à un ou plusieurs clients, qui initient des demandes pour de tels services. Les serveurs sont classés en fonction des services qu'ils fournissent. Par exemple, un serveur Web sert des pages Web et un serveur de fichiers, des fichiers informatiques. Une ressource partagée peut être n’importe quel logiciel ou composant électronique de l’ordinateur serveur, des programmes et données aux processeurs et périphériques de stockage. Le partage des ressources d’un serveur constitue un un service.
Le fait qu'un ordinateur soit un client, un serveur ou les deux dépend de la nature de l'application nécessitant les fonctions de service. Par exemple, un seul ordinateur peut exécuter simultanément un serveur Web et un logiciel de serveur de fichiers afin de fournir différentes données aux clients qui effectuent différents types de demandes. Le logiciel client peut également communiquer avec le logiciel serveur du même ordinateur.[2] La communication entre serveurs, par exemple pour synchroniser les données, est parfois appelée inter-serveur ou serveur à serveur la communication.
Communication client et serveur[[[[modifier] En général, un service est une abstraction des ressources informatiques et un client ne doit pas nécessairement se préoccuper de la façon dont le serveur exécute lorsqu’il répond à la demande et fournit la réponse. Le client doit seulement comprendre la réponse en fonction du protocole d'application bien connu, c'est-à-dire le contenu et le formatage des données pour le service demandé.
Les clients et les serveurs échangent des messages dans un modèle de messagerie demande-réponse. Le client envoie une demande et le serveur renvoie une réponse. Cet échange de messages est un exemple de communication inter-processus. Pour communiquer, les ordinateurs doivent avoir un langage commun et suivre des règles afin que le client et le serveur sachent à quoi s'attendre. Le langage et les règles de communication sont définis dans un protocole de communication. Tous les protocoles client-serveur fonctionnent dans la couche application. Le protocole de couche application définit les modèles de base du dialogue. Pour formaliser davantage l'échange de données, le serveur peut implémenter une interface de programmation d'application (API).[3] L'API est une couche d'abstraction permettant d'accéder à un service. En limitant la communication à un format de contenu spécifique, cela facilite l'analyse. En faisant abstraction de l'accès, cela facilite l'échange de données entre plates-formes.[4] Un serveur peut recevoir des demandes de nombreux clients distincts dans un court laps de temps. Un ordinateur ne peut effectuer qu'un nombre limité de tâches à tout moment, et s'appuie sur un système de planification pour hiérarchiser les demandes entrantes des clients afin de les prendre en charge. Pour éviter les abus et optimiser la disponibilité, le logiciel serveur peut limiter la disponibilité aux clients. Les attaques par déni de service sont conçues pour exploiter l'obligation d'un serveur de traiter les demandes en le surchargeant de débits excessifs.
Exemple[[[[modifier] Lorsqu'un client de la banque accède à des services bancaires en ligne à l'aide d'un navigateur Web (le client), le client envoie une demande au serveur Web de la banque. Les identifiants de connexion du client peuvent être stockés dans une base de données et le serveur Web accède au serveur de base de données en tant que client. Un serveur d'applications interprète les données renvoyées en appliquant la logique commerciale de la banque et fournit la sortie au serveur Web. Enfin, le serveur Web renvoie le résultat au navigateur Web du client pour l'affichage.
À chaque étape de cette séquence d'échanges de messages client-serveur, un ordinateur traite une demande et renvoie des données. C'est le modèle de messagerie demande-réponse. Lorsque toutes les demandes sont satisfaites, la séquence est terminée et le navigateur Web présente les données au client.
Cet exemple illustre un modèle de conception applicable au modèle client – serveur: séparation des problèmes.
Histoire ancienne[[[[modifier] Une forme ancienne d'architecture client-serveur est l'entrée de travail à distance, datant au moins de OS / 360 (annoncé en 1964), où la demande consistait à exécuter un travail et dont la réponse était la sortie.
Lors de la formulation du modèle client-serveur dans les années 1960 et 1970, les informaticiens du projet ARPANET (au Stanford Research Institute) utilisaient les termes hôte serveur (ou hôte servant) et utilisateur-hôte (ou utiliser-hôte), et ceux-ci figurent dans les premiers documents RFC 5[5] et RFC 4.[6] Cet usage a été poursuivi chez Xerox PARC au milieu des années 1970.
Les chercheurs ont utilisé ces termes pour concevoir un langage de programmation réseau appelé Decode-Encode Language (DEL).[5] Le but de ce langage était d'accepter les commandes d'un ordinateur (l'hôte utilisateur), qui renverraient des rapports d'état à l'utilisateur lors de l'encodage des commandes dans des paquets réseau. Un autre ordinateur compatible DEL, le serveur hôte, a reçu les paquets, les a décodés et a renvoyé des données formatées à l’utilisateur hôte. Un programme DEL sur l'hôte-hôte a reçu les résultats à présenter à l'utilisateur. Ceci est une transaction client-serveur. Le développement de DEL ne faisait que commencer en 1969, année de la création d'ARPANET (prédécesseur d'Internet) par le ministère de la Défense des États-Unis.
Hôte client et hôte serveur[[[[modifier] Client-hôte et hôte serveur ont des significations légèrement différentes de celles de client et serveur. Un hôte est un ordinateur connecté à un réseau. Considérant que les mots serveur et client se référer soit à un ordinateur, soit à un programme informatique, hôte serveur et utilisateur-hôte toujours se référer à des ordinateurs. L'hôte est un ordinateur multifonction polyvalent. les clients et les serveurs ne sont que des programmes qui s'exécutent sur un hôte. Dans le modèle client-serveur, un serveur est plus susceptible d'être affecté à la tâche de servir.
Une utilisation précoce du mot client apparaît dans "Séparer les données des fonctions dans un système de fichiers distribués", un article paru en 1978 par Howard Sturgis, James Mitchell et Jay Israel, informaticiens sur le PARC. Les auteurs prennent soin de définir le terme pour les lecteurs et expliquent qu'ils l'utilisent pour distinguer l'utilisateur du nœud de réseau de l'utilisateur (le client).[7] (En 1992, le mot serveur était entré dans le langage général.)[8][9] Informatique centralisée[[[[modifier] Le modèle client – serveur n'indique pas que les hôtes serveur doivent disposer de plus de ressources que les hôtes client. Au contraire, il permet à tout ordinateur à usage général d'étendre ses capacités en utilisant les ressources partagées d'autres hôtes. Cependant, l'informatique centralisée alloue spécifiquement une grande quantité de ressources à un petit nombre d'ordinateurs. Plus le calcul est déchargé des hôtes client vers les ordinateurs centraux, plus les hôtes client peuvent être simples.[10] Il fait largement appel aux ressources du réseau (serveurs et infrastructure) pour le calcul et le stockage. Un nœud sans disque charge même son système d'exploitation à partir du réseau et un terminal d'ordinateur ne possède aucun système d'exploitation. il ne s'agit que d'une interface d'entrée / sortie vers le serveur. En revanche, un client lourd, tel qu'un ordinateur personnel, dispose de nombreuses ressources et ne dépend pas d'un serveur pour des fonctions essentielles.
Alors que les prix des micro-ordinateurs ont diminué et que leur puissance a augmenté entre les années 1980 et la fin des années 1990, de nombreuses entreprises ont abandonné le calcul de serveurs centralisés, tels que des ordinateurs centraux et des mini-ordinateurs, vers des clients lourds.[11] Cela permettait une domination plus grande, plus individualisée des ressources informatiques, mais compliquait la gestion des technologies de l'information.[10][12][13] Au cours des années 2000, les applications Web ont suffisamment évolué pour rivaliser avec les logiciels d’application développés pour une microarchitecture spécifique. Cette maturation, le stockage de masse plus abordable et l'avènement de l'architecture orientée services ont été parmi les facteurs à l'origine de la tendance du cloud computing des années 2010.[14] Comparaison avec l'architecture peer-to-peer[[[[modifier] Outre le modèle client-serveur, les applications informatiques distribuées utilisent souvent l'architecture applicative poste à poste (P2P).
Dans le modèle client-serveur, le serveur est souvent conçu pour fonctionner comme un système centralisé desservant de nombreux clients. Les exigences de puissance de calcul, de mémoire et de stockage d’un serveur doivent être adaptées en fonction de la charge de travail attendue (c'est à dire., le nombre de clients se connectant simultanément). Les systèmes d'équilibrage de la charge et de basculement sont souvent utilisés pour dimensionner la mise en œuvre du serveur.[[[[citation requise] Dans un réseau d'égal à égal, deux ordinateurs ou plus (les pairs) mettent en commun leurs ressources et communiquent dans un système décentralisé. Les pairs sont des nœuds égaux ou équivalents dans un réseau non hiérarchique. Contrairement aux clients d'un réseau client – serveur ou client – file – client, les homologues communiquent directement entre eux.[15] Dans les réseaux entre homologues, un algorithme du protocole de communication entre homologues permet d'équilibrer la charge. Même les homologues dotés de ressources modestes peuvent aider à partager la charge.[15] Si un nœud devient indisponible, ses ressources partagées restent disponibles tant que d'autres homologues le proposent. Idéalement, un pair n'a pas besoin d'atteindre la haute disponibilité, car d'autres pairs redondants compensent les temps morts liés aux ressources. à mesure que la disponibilité et la capacité de charge des homologues changent, le protocole redirige les demandes.
Le client-serveur et le maître-esclave sont tous deux considérés comme des sous-catégories de systèmes distribués d'égal à égal.[16] Voir également[[[[modifier]
^ "Architecture d'application distribuée" (PDF). Sun Microsystem. Archivé de l'original (PDF) le 6 avril 2011. Récupéré 2009-06-16.
^ Le système X Window en est un exemple.
^ Benatallah, B .; Casati, F .; Toumani, F. (2004). "Modélisation de conversation de service Web: une pierre angulaire de l'automatisation du commerce électronique". IEEE Internet Computing. 8: 46–54. doi: 10.1109 / MIC.2004.1260703.
^ Dustdar, S .; Schreiner, W. (2005). "Une enquête sur la composition des services Web" (PDF). Revue internationale des services Web et de grille. 1: 1. CiteSeerX 10.1.1.139.4827. doi: 10.1504 / IJWGS.2005.007545.
^ une b Rulifson, Jeff (juin 1969). DEL. IETF. est ce que je:10.17487 / RFC0005. RFC 5. Récupéré 30 novembre 2013.
^ Shapiro, Elmer B. (mars 1969). Horaires du réseau. IETF. est ce que je:10.17487 / RFC0004. RFC 4. Récupéré 30 novembre 2013.
^ Sturgis, Howard E .; Mitchell, James George; Israël, Jay E. (1978). "Séparation des données de la fonction dans un système de fichiers distribué". Xerox PARC.
^ Harper, Douglas. "serveur". Dictionnaire d'étymologie en ligne. Récupéré 30 novembre 2013.
^ "Séparer les données de la fonction dans un système de fichiers distribué". GetInfo. Bibliothèque nationale allemande de science et technologie. Récupéré 29 novembre 2013.
^ une b Nieh, Jason; Yang, S. Jae; Novik, Naomi (2000). "Une comparaison d'architectures de calcul de client léger". Academic Commons. doi: 10.7916 / D8Z329VF. Récupéré 28 novembre 2018.
^ d'Amore, M. J .; Oberst, D. J. (1983). "Micro-ordinateurs et ordinateurs centraux". Actes de la 11ème conférence annuelle ACM SIGUCCS sur les services aux utilisateurs – SIGUCCS '83. p. 7. doi: 10.1145 / 800041.801417. ISBN 978-0897911160.
^ Tolia, Niraj; Andersen, David G .; Satyanarayanan, M. (mars 2006). "Quantification de l'expérience utilisateur interactive sur les clients légers" (PDF). Ordinateur. IEEE Computer Society. 39 (3).
^ Otey, Michael (22 mars 2011). "Le Cloud est-il vraiment juste le retour de l'informatique mainframe?". SQL Server Pro. Penton Media. Récupéré 1er décembre 2013.
^ Barros, A.P .; Dumas, M. (2006). "La montée des écosystèmes de services Web". Professionel de l'informatique. 8 (5): 31. doi: 10.1109 / MITP.2006.123.
^ une b Yongsheng, H .; Xiaoyu, T .; Zhongbin, T. (2013). "Un modèle d'optimisation pour l'interconnexion entre pairs du réseau P2P". Journal des sciences appliquées. 13 (5): 700. doi: 10.3923 / jas.2013.700.707.
^ Varma, Vasudeva (2009). "1: Introduction à l'architecture logicielle". Architecture logicielle: une approche par cas. Delhi: Pearson Education India. p. 29. ISBN 9788131707494. Récupéré 2017-07-04. Systèmes Peer-to-Peer distribués […] Il s'agit d'un style générique dont les styles populaires sont les styles client-serveur et maître-esclave.
Click to rate this post! [Total: 0 Average: 0]
Topics and keywords
Themes: Serveur d'impression
License & attribution
License: CC BY-ND 4.0.
Attribution required: yes.
Manifest: https://tutos-gameserver.fr/llm-endpoints-manifest.json
LLM Endpoints plugin version 1.1.2.