Les microservices en pratique: de l'architecture au déploiement – Bien choisir son serveur d impression
Les microservices sont l'un des mots à la mode les plus populaires dans le domaine de l'architecture logicielle. Il existe de nombreux supports d'apprentissage sur les principes fondamentaux et les avantages des microservices, mais il existe très peu de ressources sur la façon d'utiliser les microservices dans des scénarios d'entreprise réels.
Dans cet article, je vais couvrir les concepts architecturaux clés de l'architecture des microservices (MSA) et comment vous pouvez utiliser ces principes architecturaux dans la pratique.
Sommaire
Architecture monolithique
Les applications logicielles d'entreprise sont conçues pour faciliter de nombreuses exigences commerciales; une application logicielle donnée offre des centaines de fonctionnalités et toutes ces fonctionnalités sont empilées dans une seule application monolithique. Par exemple, les ERP, les CRM et divers autres systèmes logiciels sont construits comme un monolithe avec plusieurs centaines de fonctionnalités. Le déploiement, le dépannage, la mise à l'échelle et la mise à niveau de ces applications logicielles monstrueuses est un cauchemar.
L'architecture orientée services (SOA) a été conçue pour surmonter certaines des limitations susmentionnées en introduisant le concept de service, une agrégation et un regroupement de fonctionnalités similaires offertes à partir d'une application. Avec SOA, une application logicielle est conçue comme une combinaison de services à granularité grossière. Cependant, dans SOA, la portée d'un service est très large. Cela conduit à des services complexes et gigantesques avec plusieurs dizaines d'opérations (fonctionnalités), ainsi que des formats de message et des normes complexes (par exemple: toutes les normes WS *).
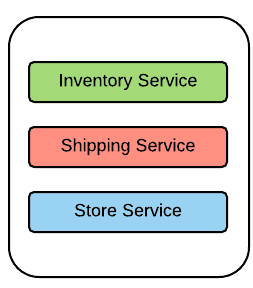
Dans la plupart des cas, les services SOA sont indépendants les uns des autres; pourtant, ils sont déployés dans le même runtime avec tous les autres services (pensez simplement à avoir plusieurs applications Web qui sont déployées dans la même instance Tomcat). Semblables aux applications logicielles monolithiques, ces services ont l'habitude de se développer au fil du temps en accumulant diverses fonctionnalités. Littéralement, cela transforme ces applications en globes monolithiques qui ne sont pas différents des applications monolithiques conventionnelles telles que les ERP. Le montre une application logicielle de vente au détail qui comprend plusieurs services. Tous ces services sont déployés dans le même runtime d'application. C'est donc un très bon exemple d'architecture monolithique. Voici quelques caractéristiques des applications basées sur une architecture monolithique.
- Les applications monolithiques sont conçues, développées et déployées comme une seule unité.
- Les applications monolithiques sont extrêmement complexes; cela conduit à des cauchemars dans le maintien, la mise à niveau et l'ajout de nouvelles fonctionnalités.
- Il est difficile de pratiquer des méthodologies de développement et de livraison agiles avec une architecture monolithique.
- Il est nécessaire de redéployer l'intégralité de l'application afin d'en mettre à jour une partie.
- L'application doit être mise à l'échelle comme une seule unité, ce qui rend difficile la gestion des exigences de ressources conflictuelles (par exemple, un service nécessite plus de CPU, tandis que l'autre nécessite plus de mémoire)
- Un service instable peut faire tomber toute l'application.
- Il est vraiment difficile d'adopter de nouvelles technologies et de nouveaux cadres, car toutes les fonctionnalités doivent s'appuyer sur des technologies / cadres homogènes.
Architecture des microservices
La base de l'architecture de microservices (MSA) consiste à développer une seule application en tant que suite de petits services indépendants qui sont exécutés dans leur propre processus, développés et déployés de manière indépendante.
Dans la plupart des définitions de l'architecture des microservices, elle est expliquée comme le processus de séparation des services disponibles dans le monolithe en un ensemble de services indépendants. Cependant, à mon avis, les microservices ne consistent pas seulement à diviser les services disponibles dans monolith en services indépendants.
L'idée clé est qu'en examinant les fonctionnalités offertes par le monolithe, nous pouvons identifier les capacités commerciales requises. Ces capacités commerciales peuvent ensuite être mises en œuvre en tant que (micro) services entièrement indépendants, à granularité fine et autonomes. Ils peuvent être mis en œuvre sur différentes piles technologiques et chaque service s'adresse à un domaine d'activité très spécifique et limité.
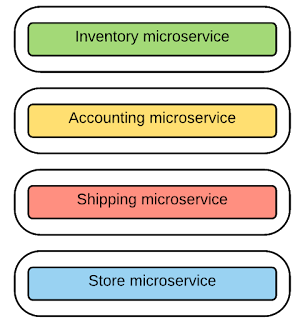
Par conséquent, le scénario de système de vente au détail en ligne que nous expliquons ci-dessus peut être réalisé avec une architecture de microservices, comme illustré dans la figure ci-dessous. Avec une architecture de microservices, l'application logicielle de vente au détail est implémentée comme une suite de microservices. Ainsi, comme vous pouvez le voir ci-dessous, en fonction des besoins de l'entreprise, il existe un microservice supplémentaire créé à partir de l'ensemble de services d'origine qui se trouvent dans le monolithe. Il est donc tout à fait évident que l'utilisation de l'architecture de microservices va au-delà du fractionnement des services dans le monolithe.
Plongeons-nous dans les principes architecturaux clés des microservices et, plus important encore, concentrons-nous sur la façon dont ils peuvent être utilisés dans la pratique.
Conception de microservices: taille, portée et capacités
Vous pouvez créer votre application logicielle à partir de zéro en utilisant une architecture de microservices ou convertir des applications / services existants en microservices. Quoi qu'il en soit, il est très important que vous décidiez correctement de la taille, de la portée et des capacités des microservices. C'est probablement la chose la plus difficile que vous rencontrez au départ lorsque vous implémentez l'architecture des microservices dans la pratique.
Voyons quelques-unes des principales préoccupations pratiques et idées fausses liées à la taille, à la portée et aux capacités des microservices.
- Les lignes de code / la taille de l'équipe sont des mesures pourries: Il y a plusieurs discussions sur la décision de la taille des microservices en fonction des lignes de code de sa mise en œuvre ou de la taille de son équipe (c'est-à-dire l'équipe de deux pizzas). Cependant, ceux-ci sont considérés comme des métriques très peu pratiques et moche, car nous pouvons toujours développer des services avec moins de code / avec une taille de deux équipes de pizza mais violant totalement les principes architecturaux du microservice.
- "Micro" est un terme un peu trompeur: La plupart des développeurs ont tendance à penser qu'ils devraient essayer de rendre le service aussi petit que possible. C'est une idée fausse.
- Contexte SOA: Dans le contexte SOA, les services sont souvent implémentés sous forme de globes monolithiques avec la prise en charge de plusieurs dizaines d'opérations / fonctionnalités. Donc, avoir des services de type SOA et les renommer en microservices ne vous procurera aucun avantage de l'architecture des microservices.
Alors, comment devrions-nous concevoir correctement les services dans l'architecture des microservices?
Lignes directrices pour la conception de microservices
- Principe de responsabilité unique (SRP): Avoir une portée commerciale limitée et ciblée pour un microservice nous aide à répondre à l'agilité dans le développement et la prestation de services.
- Pendant la phase de conception des microservices, nous devons trouver leurs limites et les aligner avec les capacités métier (également appelées contexte borné dans Domain-Driven-Design).
- Assurez-vous que la conception des microservices assure le développement et le déploiement agiles / indépendants du service.
- Notre objectif devrait être la portée du microservice, mais pas la réduction du service. La taille (à droite) du service doit être la taille requise pour faciliter une capacité commerciale donnée.
- Contrairement au service SOA, un microservice donné doit avoir très peu d'opérations / fonctionnalités et un format de message simple.
- C'est souvent une bonne pratique de commencer par des limites de services relativement larges pour commencer, puis de refactoriser les plus petites (en fonction des besoins de l'entreprise) au fil du temps.
Dans notre cas d'utilisation au détail, vous pouvez constater que nous avons divisé les fonctionnalités du monolithe en quatre microservices différents, à savoir "inventaire", "comptabilité", "expédition" et "magasin". Ils s'adressent à un périmètre d'activité limité mais ciblé afin que chaque service soit complètement découplé les uns des autres et assure l'agilité dans le développement et le déploiement.
Messagerie dans les microservices
Dans les applications monolithiques, les fonctionnalités métier de différents processeurs / composants sont appelées à l'aide d'appels de fonction ou d'appels de méthode au niveau du langage. Dans SOA, cela a été déplacé vers une messagerie au niveau du service Web beaucoup plus faiblement couplée, qui est principalement basée sur SOAP au-dessus de différents protocoles tels que HTTP, JMS. Les services Web avec plusieurs dizaines d'opérations et schémas de messages complexes étaient une force résistive clé pour la popularité des services Web. Pour l'architecture des microservices, il est nécessaire d'avoir un mécanisme de messagerie simple et léger.
Messagerie synchrone – REST, Thrift
Pour la messagerie synchrone (le client attend une réponse opportune du service et attend qu'il l'obtienne) dans Microservices Architecture, REST est le choix unanime car il fournit un style de messagerie simple implémenté avec la réponse-requête HTTP, basé sur le style API de ressource. Par conséquent, la plupart des implémentations de microservices utilisent HTTP avec des styles basés sur l'API de ressources (chaque fonctionnalité est représentée avec une ressource et des opérations effectuées au-dessus de ces ressources).
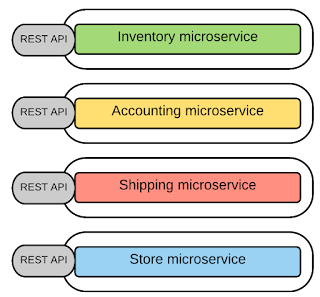
Thrift est utilisé (dans lequel vous pouvez définir une définition d'interface pour votre microservice), comme alternative à la messagerie synchrone REST / HTTP.
Messagerie asynchrone – AMQP, STOMP, MQTT
Pour certains scénarios de microservices, il est nécessaire d'utiliser des techniques de messagerie asynchrone (le client n'attend pas de réponse immédiatement ou n'accepte aucune réponse du tout). Dans de tels scénarios, les protocoles de messagerie asynchrones tels que AMQP, STOMP ou MQTT sont largement utilisés.
Formats des messages – JSON, XML, Thrift, ProtoBuf, Avro
Décider du meilleur format de message pour les microservices est un autre facteur clé. Les applications monolithiques traditionnelles utilisent des formats binaires complexes, les applications basées sur les services SOA / Web utilisent des messages texte basés sur des formats de messages complexes (SOAP) et des schémas (xsd). Dans la plupart des applications basées sur des microservices, ils utilisent des formats de message texte simples, tels que JSON et XML, en plus du style API de ressources HTTP. Dans les cas où nous avons besoin de formats de messages binaires (les messages texte peuvent devenir verbeux dans certains cas d'utilisation), les microservices peuvent tirer parti des formats de messages binaires tels que Thrift binaire, ProtoBuf ou Avro.
Contrats de service – Définition des interfaces de service – Swagger, RAML, Thrift IDL
Lorsque vous avez une capacité métier implémentée en tant que service, vous devez définir et publier le contrat de service. Dans les applications monolithiques traditionnelles, nous trouvons à peine de telles fonctionnalités pour définir les capacités commerciales d'une application. Dans le monde des services SOA / Web, WSDL est utilisé pour définir le contrat de service, mais, comme nous le savons tous, WSDL n'est pas la solution idéale pour définir un contrat de microservices car WSDL est incroyablement complexe et étroitement couplé à SOAP.
Puisque nous construisons des microservices au-dessus d'un style architectural REST, nous pouvons utiliser les mêmes techniques de définition d'API REST pour définir le contrat des microservices. Par conséquent, les microservices utilisent les langages de définition d'API REST standard, tels que Swagger et RAML pour définir les contrats de service.
Pour d'autres implémentations de microservices qui ne sont pas basées sur HTTP / REST (telles que Thrift), nous pouvons utiliser les langages de définition d'interface (IDL) au niveau du protocole (par exemple: Thrift IDL).
Intégration de microservices (communication interservices / processus)
Dans l'architecture des microservices, les applications logicielles sont conçues comme une suite de services indépendants. Ainsi, afin de réaliser un cas d'utilisation métier, il est nécessaire d'avoir les structures de communication entre les différents microservices / processus. C'est pourquoi la communication interservices / processus entre microservices est un aspect si vital.
Dans les implémentations SOA, la communication interservices entre les services est facilitée par un ESB (Enterprise Service Bus) et la majeure partie de la logique métier réside dans la couche intermédiaire (routage, transformation et orchestration des messages). Cependant, l'architecture des microservices permet d'éliminer le bus de messages central / ESB et de déplacer la «logique intelligente» ou la logique métier vers les services et le client (appelés Smart Endpoints).
Étant donné que les microservices utilisent des protocoles standard tels que HTTP, JSON, etc., l'exigence d'intégration avec un protocole disparate est minime en ce qui concerne la communication entre les microservices. Une autre approche alternative dans la communication de microservices consiste à utiliser un bus de messages léger ou une passerelle avec des capacités de routage minimales et à agir comme un «canal muet» sans logique métier implémentée sur la passerelle. Sur la base de ces styles, plusieurs modèles de communication ont émergé dans l'architecture des microservices.
Style point à point – Appel direct de services
Dans un style point à point, l'intégralité de la logique de routage des messages réside sur chaque point d'extrémité et les services peuvent communiquer directement. Chaque microservice expose une API REST et un microservice donné ou un client externe peut invoquer un autre microservice via son API REST.

De toute évidence, ce modèle fonctionne pour des applications basées sur des microservices relativement simples, mais à mesure que le nombre de services augmente, cela deviendra extrêmement complexe. Après tout, c'est la raison exacte pour laquelle utiliser ESB dans l'implémentation SOA traditionnelle: pour se débarrasser des liens d'intégration point à point compliqués. Essayons de résumer les principaux inconvénients du style point à point pour la communication de microservices.
- Les exigences non fonctionnelles telles que l'authentification de l'utilisateur final, la limitation, la surveillance, etc. doivent être mises en œuvre à chaque niveau de microservice.
- Du fait de la duplication de fonctionnalités communes, chaque implémentation de microservices peut devenir complexe.
- Il n'y a aucun contrôle sur la communication entre les services et les clients (même pour la surveillance, le traçage ou le filtrage)
- Souvent, le style de communication directe est considéré comme un anti-modèle de microservice pour les implémentations de microservices à grande échelle.
Par conséquent, pour les cas d'utilisation complexes de microservices, plutôt que d'avoir une connectivité point à point ou un ESB central, nous pourrions avoir un bus de messagerie central léger qui peut fournir une couche d'abstraction pour les microservices et qui peut être utilisé pour implémenter divers non fonctionnels capacités. Ce style est appelé style API Gateway.
Style de passerelle API
L'idée clé derrière le style API Gateway est d'utiliser une passerelle de messages légère comme point d'entrée principal pour tous les clients / consommateurs et de mettre en œuvre les exigences non fonctionnelles communes au niveau de la passerelle. En général, une passerelle API vous permet de consommer une API gérée via REST / HTTP. Par conséquent, ici, nous pouvons exposer nos fonctionnalités commerciales qui sont implémentées en tant que microservices, via l'API-GW, en tant qu'API gérées. En fait, c'est une combinaison d'architecture de microservices et de gestion des API qui vous offre le meilleur des deux mondes.
Dans notre scénario de commerce de détail, comme illustré dans la figure ci-dessus, tous les microservices sont exposés via un API-GW et c'est le point d'entrée unique pour tous les clients. Si un microservice veut consommer un autre microservice, cela doit également être fait via l'API-GW. Le style API-GW vous offre les avantages suivants: Le style API-GW pourrait bien être le modèle le plus utilisé dans la plupart des implémentations de microservices. Les microservices peuvent être intégrés à un scénario de messagerie asynchrone tel que les requêtes unidirectionnelles et la messagerie publication-abonnement à l'aide de files d'attente ou de rubriques. Un microservice donné peut être le producteur de messages et il peut envoyer des messages de manière asynchrone vers une file d'attente ou une rubrique. Le microservice consommateur peut alors consommer les messages de la file d'attente ou de la rubrique. Ce style dissocie les producteurs de messages des consommateurs de messages et le courtier de messages intermédiaire tamponne les messages jusqu'à ce que le consommateur soit en mesure de les traiter. Les microservices des producteurs ignorent totalement les microservices des consommateurs. La communication entre les consommateurs / producteurs est facilitée par un courtier de messages basé sur des normes de messagerie asynchrones telles que AMQP, MQTT, etc. Dans une architecture monolithique, l'application stocke les données dans une base de données unique et centralisée pour implémenter diverses fonctionnalités / capacités de l'application. Dans l'architecture des microservices, les fonctionnalités sont dispersées sur plusieurs microservices et, si nous utilisons la même base de données centralisée, alors les microservices ne seront plus indépendants les uns des autres (par exemple, si le schéma de la base de données a changé d'un microservice donné, cela cassera plusieurs autres services). Par conséquent, chaque microservice doit avoir sa propre base de données. Voici les principaux aspects de la mise en œuvre de la gestion décentralisée des données dans l'architecture de microservices. La gestion décentralisée des données vous donne les microservices entièrement découplés et la liberté de choisir des techniques de gestion des données disparates (SQL ou NoSQL etc., différents systèmes de gestion de base de données pour chaque service). Cependant, pour les cas d'utilisation transactionnels complexes qui impliquent plusieurs microservices, le comportement transactionnel doit être mis en œuvre à l'aide des API proposées par chaque service et la logique réside au niveau du client ou de l'intermédiaire (GW). L'architecture des microservices favorise la gouvernance décentralisée. En général, la «gouvernance» signifie établir et appliquer la façon dont les personnes et les solutions travaillent ensemble pour atteindre les objectifs organisationnels. Dans le contexte de la SOA, la gouvernance SOA guide le développement de services réutilisables, établissant comment les services seront conçus et développés et comment ces services évolueront avec le temps. Il établit des accords entre les fournisseurs de services et les consommateurs de ces services, indiquant aux consommateurs ce qu'ils peuvent attendre et aux fournisseurs ce qu'ils sont tenus de fournir. Dans SOA Governance, deux types de gouvernance sont couramment utilisés: Alors, que signifie vraiment la gouvernance dans un contexte de microservices? Dans l'architecture des microservices, les microservices sont conçus comme des services entièrement indépendants et découplés avec une variété de technologies et de plates-formes. Il n'est donc pas nécessaire de définir une norme commune pour la conception et le développement des services. Ainsi, nous pouvons résumer les capacités de gouvernance décentralisée des microservices comme suit: Dans l'architecture des microservices, le nombre de microservices que vous devez gérer est assez élevé. Et aussi, leurs emplacements changent dynamiquement en raison de la nature de développement / déploiement rapide et agile des microservices. Par conséquent, vous devez trouver l'emplacement d'un microservice pendant l'exécution. La solution à ce problème consiste à utiliser un registre de service. Service Registry contient les instances de microservices et leurs emplacements. Les instances de microservice sont enregistrées auprès du registre de service au démarrage et annulées à l'arrêt. Les consommateurs peuvent trouver les microservices disponibles et leurs emplacements via le registre de services. Pour trouver les microservices disponibles et leur emplacement, nous devons disposer d'un mécanisme de découverte de service. Il existe deux types de mécanismes de découverte de service, la découverte côté client et la découverte côté serveur. Examinons de plus près ces mécanismes de découverte de services. Découverte côté client – Dans cette approche, le client ou l'API-GW obtient l'emplacement d'une instance de service en interrogeant un registre de services. Découverte côté serveur – Avec cette approche, clients / API-GW envoie la demande à un composant (tel qu'un équilibreur de charge) qui s'exécute sur un emplacement bien connu. Ce composant appelle le registre de services et détermine l'emplacement absolu du microservice.
Tous les microservices sont exposés via un API-GW
Style de courtier de messages

Gestion décentralisée des données


Gouvernance décentralisée
Registre de services et découverte de services
Registre des services
Découverte de service

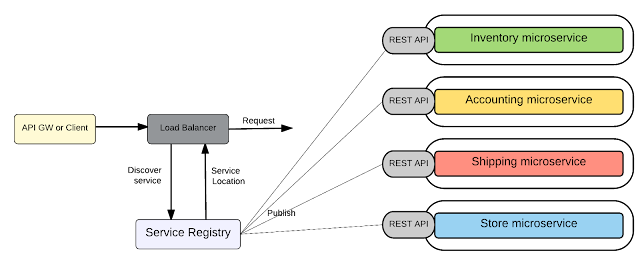 Découverte côté client
Découverte côté client
Les solutions de déploiement de microservices, telles que Kubernetes (http://kubernetes.io/v1.1/docs/user-guide/services.html), offrent des mécanismes de découverte côté service.
Déploiement
En ce qui concerne l'architecture des microservices, le déploiement des microservices joue un rôle critique et présente les exigences clés suivantes:
- Possibilité de déployer / de-déployer indépendamment des autres microservices.
- Doit pouvoir évoluer à chaque niveau de microservices (un service donné peut obtenir plus de trafic que d'autres services).
- Création et déploiement rapides de microservices.
- La défaillance d'un microservice ne doit affecter aucun des autres services.
Docker (un moteur open source qui permet aux développeurs et aux administrateurs système de déployer des conteneurs d'applications autonomes dans les environnements Linux) offre un excellent moyen de déployer des microservices répondant aux exigences ci-dessus. Les étapes clés impliquées sont les suivantes:
- Empaquetez le microservice en tant qu’image de conteneur (Docker).
- Déployez chaque instance de service en tant que conteneur.
- La mise à l'échelle se fait en fonction de la modification du nombre d'instances de conteneurs.
- La construction, le déploiement et le démarrage du microservice seront beaucoup plus rapides car nous utilisons des conteneurs Docker (ce qui est beaucoup plus rapide qu'une machine virtuelle ordinaire)
Kubernetes étend les capacités de Docker en permettant de gérer un cluster de conteneurs Linux en tant que système unique, en gérant et en exécutant des conteneurs Docker sur plusieurs hôtes, en offrant la co-localisation des conteneurs, la découverte de services et le contrôle de la réplication. Comme vous pouvez le voir, la plupart de ces fonctionnalités sont également essentielles dans notre contexte de microservices. Par conséquent, l'utilisation de Kubernetes (en plus de Docker) pour le déploiement de microservices est devenue une approche extrêmement puissante, en particulier pour les déploiements de microservices à grande échelle.

Dans la figure ci-dessus, il présente une vue d'ensemble du déploiement des microservices de l'application commerciale. Chaque instance de microservice est déployée en tant que conteneur et il existe deux conteneurs par hôte. Vous pouvez modifier arbitrairement le nombre de conteneurs que vous exécutez sur un hôte donné.
Sécurité
La sécurisation des microservices est une exigence assez courante lorsque vous utilisez des microservices dans des scénarios réels. Avant de passer à la sécurité des microservices, voyons comment nous implémentons normalement la sécurité au niveau de l'application monolithique.
- Dans une application monolithique typique, la sécurité consiste à trouver «qui est l'appelant», «que peut faire l'appelant» et «comment diffuser ces informations».
- Ceci est généralement implémenté au niveau d'un composant de sécurité commun qui se trouve au début de la chaîne de traitement des demandes et ce composant remplit les informations requises avec l'utilisation d'un référentiel d'utilisateurs (ou magasin d'utilisateurs) sous-jacent.
Alors, pouvons-nous traduire directement ce modèle dans l'architecture des microservices? Oui, mais cela nécessite un composant de sécurité implémenté à chaque niveau de microservices qui parle à un référentiel d'utilisateurs centralisé / partagé et récupère les informations requises. C'est une approche très fastidieuse pour résoudre le problème de sécurité des microservices. Au lieu de cela, nous pouvons tirer parti des normes de sécurité API largement utilisées telles que OAuth2 et OpenID Connect pour trouver une meilleure solution à notre problème de sécurité des microservices. Avant d'approfondir cela, permettez-moi de résumer simplement l'objectif de chaque norme et comment nous pouvons les utiliser.
- OAuth2 – Est un protocole de délégation d'accès. Le client s'authentifie auprès du serveur d'autorisation et obtient un jeton opaque appelé «jeton d'accès». Un jeton d'accès ne contient aucune information sur l'utilisateur / client. Il contient uniquement une référence aux informations utilisateur qui ne peuvent être récupérées que par le serveur d'autorisation. Par conséquent, cela est connu comme un « jeton de référence '' et il est sûr d'utiliser ce jeton même dans le réseau public / Internet.
- OpenID Connect se comporte de manière similaire à OAuth, mais, en plus du jeton d'accès, le serveur d'autorisation émet un jeton ID qui contient des informations sur l'utilisateur. Ceci est souvent implémenté par un JWT (JSON Web Token) et qui est signé par un serveur d'autorisation. Ainsi, cela garantit la confiance entre le serveur d'autorisation et le client. Le jeton JWT est donc connu comme un « jeton par valeur '' car il contient les informations de l'utilisateur et n'est évidemment pas sûr de l'utiliser en dehors du réseau interne.
Voyons maintenant comment utiliser ces normes pour sécuriser les microservices dans notre exemple de vente au détail.

Comme le montre la figure ci-dessus, voici les étapes clés de la mise en œuvre de la sécurité des microservices:
- Laissez l'authentification à OAuth et au serveur OpenID Connect (Authorization Server), afin que les microservices fournissent un accès avec succès, étant donné que quelqu'un a le droit d'utiliser les données.
- Utilisez le style API-GW, dans lequel il existe un point d'entrée unique pour toutes les demandes des clients.
- Le client se connecte au serveur d'autorisation et obtient le jeton d'accès (jeton de référence). Envoyez ensuite le jeton d'accès à l'API-GW avec la demande.
- Traduction de jeton à la passerelle – API-GW extrait le jeton d'accès et l'envoie au serveur d'autorisation pour récupérer le JWT (par jeton de valeur).
- Ensuite, GW transmet ce JWT avec la demande à la couche microservices.
- Les JWT contiennent les informations nécessaires pour aider au stockage des sessions utilisateur, etc. Si chaque service peut comprendre un jeton Web JSON, alors vous avez distribué votre mécanisme d'identité qui vous permet de transporter l'identité à travers votre système.
- À chaque couche de microservices, nous pouvons avoir un composant qui traite le JWT, ce qui est une implémentation assez banale.
Transactions
Qu'en est-il du support des transactions dans les microservices? En fait, la prise en charge des transactions distribuées sur plusieurs microservices est une tâche exceptionnellement complexe. L'architecture de microservice elle-même encourage la coordination sans transaction entre les services.
L'idée est qu'un service donné est entièrement autonome et basé sur le principe de la responsabilité unique. La nécessité d'avoir des transactions distribuées sur plusieurs microservices est souvent le symptôme d'une faille de conception dans l'architecture de microservices et peut généralement être triée en refactorisant les étendues des microservices. Cependant, s'il existe une exigence obligatoire d'avoir des transactions distribuées sur plusieurs services, de tels scénarios peuvent être réalisés avec l'introduction d '«opérations de compensation» à chaque niveau de microservice. L'idée clé est qu'un microservice donné est basé sur le principe de la responsabilité unique et si un microservice donné n'a pas réussi à exécuter une opération donnée, nous pouvons considérer cela comme une défaillance de l'ensemble du microservice. Ensuite, toutes les autres opérations (en amont) doivent être annulées en invoquant l'opération de compensation respective de ces microservices.
Conception pour les échecs
L'architecture de microservices introduit un ensemble dispersé de services et, par rapport à une conception monolithique, augmente la possibilité de défaillances à chaque niveau de service. Un microservice donné peut échouer en raison de problèmes de réseau, de l'indisponibilité des ressources sous-jacentes, etc. Un microservice indisponible ou ne répondant pas ne devrait pas entraîner l'arrêt complet de l'application basée sur les microservices. Ainsi, les microservices doivent être tolérants aux pannes, pouvoir récupérer lorsque cela est possible et le client doit les gérer avec élégance.
De plus, comme les services peuvent échouer à tout moment, il est important de pouvoir détecter (surveillance en temps réel) les défaillances rapidement et, si possible, restaurer automatiquement les services.
Il existe plusieurs modèles couramment utilisés pour gérer les erreurs dans un contexte de microservices.
Disjoncteur
Lorsque vous effectuez un appel externe vers un microservice, vous configurez un composant de surveillance des pannes à chaque appel et lorsque les échecs atteignent un certain seuil, ce composant arrête toute autre invocation du service (déclenche le circuit). Après un certain nombre de demandes en état ouvert (que vous pouvez configurer), remettez le circuit en état fermé.
Ce modèle est très utile pour éviter la consommation inutile de ressources, les retards de demande dus aux délais d'attente et nous donne également la possibilité de surveiller le système (en fonction des états des circuits ouverts actifs).
Cloison
Étant donné que l'application de microservices comprend le nombre de microservices, les défaillances d'une partie de l'application basée sur les microservices ne doivent pas affecter le reste de l'application. Le modèle de cloison consiste à isoler différentes parties de votre application, de sorte qu'une défaillance d'un service dans l'application n'affecte aucun des autres services.
Temps libre
Le modèle de délai d'attente est un mécanisme qui vous permet d'arrêter d'attendre une réponse du microservice lorsque vous pensez qu'elle ne viendra pas. Ici, vous pouvez configurer l'intervalle de temps que vous souhaitez attendre.
Alors, où et comment utilisons-nous ces modèles avec des microservices? Dans la plupart des cas, la plupart de ces modèles sont applicables au niveau de la passerelle. Ce qui signifie que lorsque les microservices ne sont pas disponibles ou ne répondent pas, au niveau de la passerelle, nous pouvons décider d'envoyer la demande au microservice à l'aide de disjoncteurs ou d'un modèle de délai d'expiration. De plus, il est très important de mettre en place des modèles tels que la cloison étanche au niveau de la passerelle, car c'est le point d'entrée unique pour toutes les demandes des clients, donc une défaillance dans un service de distribution ne devrait pas affecter l'invocation des autres microservices.
De plus, la passerelle peut être utilisée comme point central pour obtenir l'état et le contrôle de chaque microservice lorsque chaque microservice est appelé via la passerelle.
Microservices, intégration d'entreprise, gestion des API et au-delà.
We have discusse various characteristics of Microservices architecture and how you could implement them in the modern enterprise IT landscape. However, we should keep in mind that Microservices is not a panacea. The blind adaptation of buzzword concepts is not going to solve your 'real' Enterprise IT problems. As you have seen throughout this blog post, there are quite a lot of advantages of microservices and we should leverage. But, we also have to keep in mind that it is not realistic to solve all the enterprise IT problems with microservics. For instance, Microservices architecture promotes to eliminate ESB as the central bus, but when it comes to real world IT, there are quite a lot of existing applications/services which are not based on Microservices. So, to integrate with them, we need some sort of integration bus. So, ideally, a hybrid approach of Microservices and other enterprise architectural concepts such as Integration would be more realistic. I will discuss them further in a separate blog post.
Hope this gives you a much clearer idea of how you can use Microservices in your enterprises.
This post was originally published on February 19th, 2016.






Commentaires
Laisser un commentaire