Bonjour à tous,
J'aborderai plusieurs articles qui seront liés au stockage dans Windows Server 2012 R2.
Nous verrons d'abord la déduplication des données, son fonctionnement et un test sur Windows Server 2012 R2.
Ensuite, je vous montre la configuration et l'implémentation de la déduplication. (qui sera dans la partie 2)
PARTIE 1 DÉDUPLICATION – Fonctionnement:
Server 2012 R2:
mots, existe depuis de nombreuses
années, mais encore peu connues, Microsoft a décidé de l'intégrer dans son système
Systèmes d'exploitation Windows Server 2012 et 2012 R2.
vont être en mesure de résoudre un gros problème, qui est l'explosion des données, aujourd'hui dans les systèmes d'information, nous avons trop de données:
utilisateurs
etc)
– Logiciel, etc.
Magasins de déduplication
plus de données dans moins d'espace.
déduplication:
fichiers en petits morceaux de taille variable (32-128 Ko), les doublons sont
identifiés et conservés en un seul exemplaire, ils sont compressés puis mis en
fichiers spéciaux.
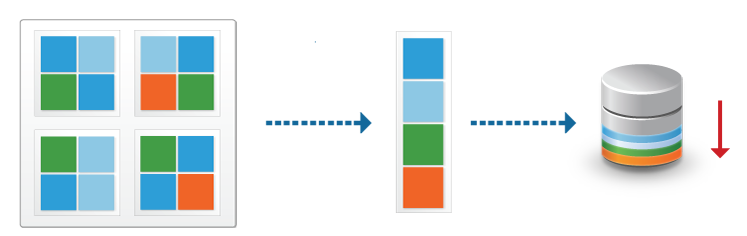
nous
voir ici, les données après activation de la déduplication, sont stockées
une seule fois, ils sont compressés et placés dans des fichiers spéciaux. il
il existe une création de référence pour éviter les doublons
la déduplication permet de segmenter les données stockées, ainsi, les données sont
se voient attribuer un identifier unique,
cela permettra de comparer les identifiants des autres données stockées, si
l'identifier est unique, il est stocké directement sur l'espace de stockage.
contre, si nous stockons à nouveau des données et que lors de la vérification, nous
se retrouve avec un identifiant similaire (donc il y a des données en double),
ces données ne seront pas stockées sur l'espace de stockage, mais il y aura
une référence (aiguille) aux données existantes, afin d'éviter
doublons.
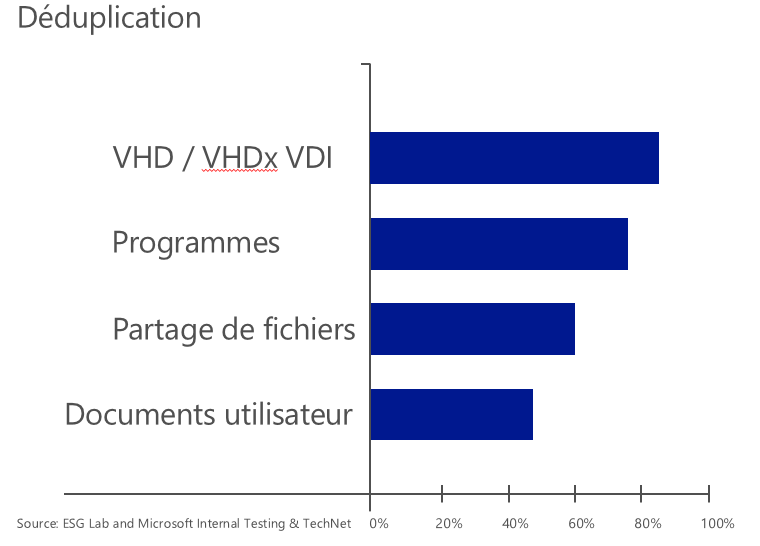
énorme gain de place, voici une étude réalisée dans les laboratoires de Microsoft
qui montre les gains qui peuvent être réalisés dans un environnement de
production:
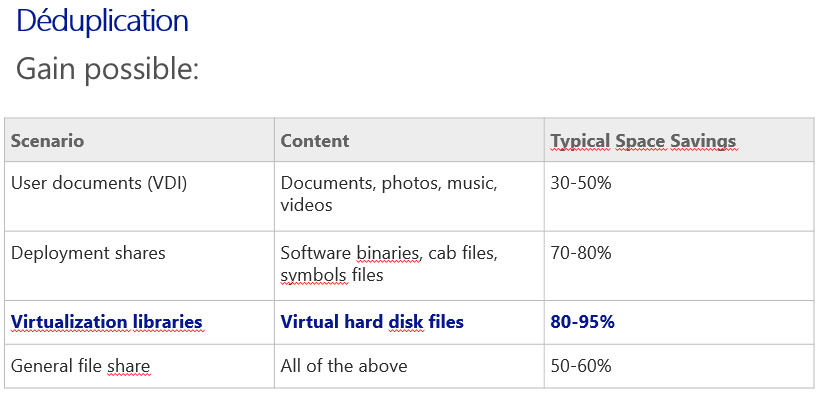
Voici un tableau de TechNet qui résume également
économies d'espace de stockage possibles grâce à la déduplication sous Windows
Server 2012 R2:
Cependant, il existe des scénarios
ou il n'est pas recommandé d'utiliser la déduplication, nous verrons dans quel
dans ce cas, il sera possible d'utiliser la déduplication et vice versa.
Déduplication avec Windows Server 2012 R2:
- Partage de déploiement
binaire (logiciel) - Serveur
des dossiers - Également pris en charge
avec Storage CSV utilisé dans SOFS - Environnement de
virtualisation / VDI - Librairies
virtualisation (SCVMM)
- Serveur SQL
- Serveur d'échange
- Disque système
(disque de démarrage) - 2 Implémentation de la déduplication
Avant d'appliquer le
deduplciation au sein de vos serveurs Windows Server 2012R2, il est recommandé
pour évaluer la quantité de stockage que vous gagnerez grâce à la
déduplication, il y a un très joli petit outil (DDPEVAL.exe) qui vous aidera à évaluer
et quantifier les gains possibles après déduplication.
Pour ce faire, installez
la déduplication des données fonctionnalisée sur le (s) serveur (s):
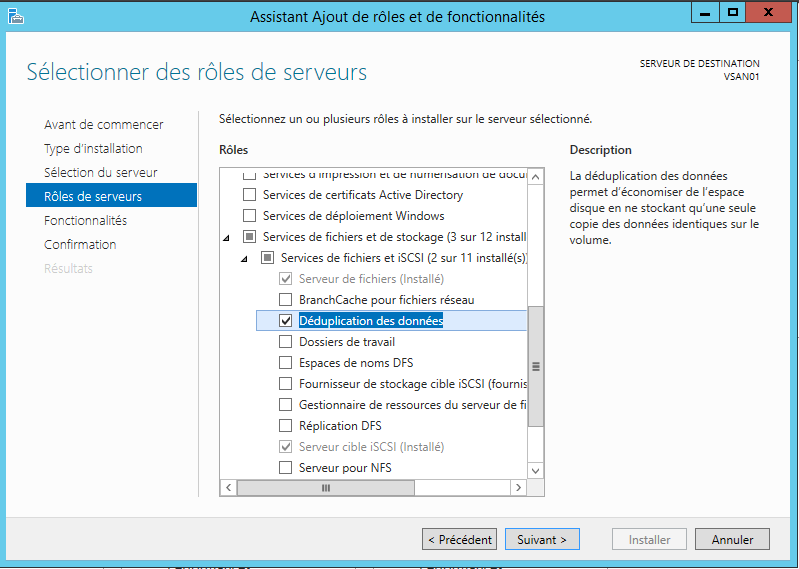
est installé, vous pourrez utiliser l'outil d'évaluation ==> DDPEVAL.EXE
suivant :
fait sur l'un de mes serveurs de stockage: (sur Windows Server
2012 R2).
commande, outil processus à l'évaluation du gain de stockage que nous pouvons
avoir :

Je vais te prouver
l'efficacité de la déduplication dans Windows Server 2012 R2:
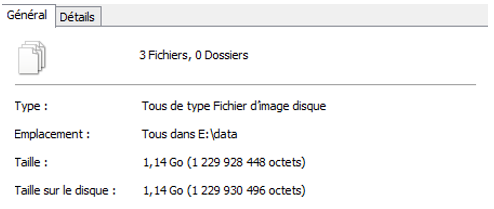
J'ai dans le dossier E: DATA 3
fichiers avec un total de 1,14 Go.
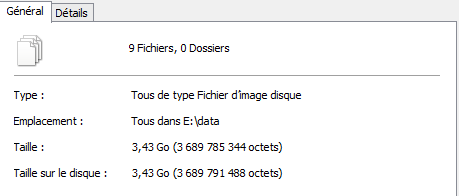
donc j'aurais 9 fiches avec une taille totale d'espace disque consommé qui
est à propos 3,44 Go. (1,14 * 3 = 3,42)
Je vais appliquer l'outil d'évaluation de l'éducation de
données sur mon disque E: data et nous verrons ce qui va se passer:
Voici la commande: DDPEval.exe E: data
de l'évaluation:
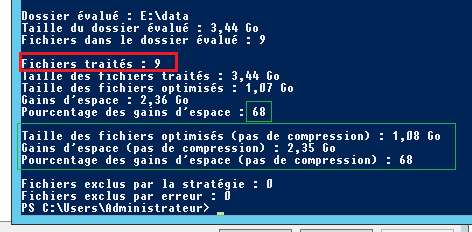
traité, c'est le nombre de fichiers que j'ai dans le dossier E: data.
la déduplication identifie qu'il y a donc des doublons (même identifiant dans
données), de sorte qu'il optimise tout et stocke les données une seule fois, et
nous allons donc nous retrouver avec seulement les 3 premiers fichiers qui seront
stockées sur le disque, les deux autres copies ne seront pas stockées, mais seront
accessible via des références qui pointeront vers les 3 fichiers originaux.
Cette
est vérifiée, car la taille optimisée sera 1.07
Aller, ce qui correspond à la taille de départ des trois fichiers (1,14 Go).
Le gain de stockage avec déduplication dans ce cas sera 2,36 Go, cC'est-à-dire 68%.
est vrai parce que si nous le faisons 1,07 + 2,36 =
3.44 et 3.44 est la valeur de départ des 9 fichiers de départ.
Voila, la première partie est terminée, nous verrons dans un prochain article la mise en place et la configuration de la déduplication des données dans Windows Server 2012 R2.
@ bientôt Seyfallah Tagrerout






Commentaires
Laisser un commentaire