
Lorsque vous souhaitez utiliser Linux pour fournir des services à une entreprise, ces services doivent être sécurisés, résilients et évolutifs. Jolis mots, mais que voulons-nous dire par eux?
«Sécurisé» signifie que les utilisateurs peuvent accéder aux données dont ils ont besoin, qu'il s'agisse d'un accès en lecture seule ou d'un accès en écriture. Dans le même temps, aucune donnée n'est exposée à une partie qui n'est pas autorisée à les voir. La sécurité est trompeuse: vous pouvez penser que vous avez tout protégé pour découvrir plus tard qu'il y a des trous. Concevoir en sécurité dès le début d'un projet est beaucoup plus facile que d'essayer de le moderniser plus tard.
«Résilient» signifie que vos services tolèrent les défaillances au sein de l'infrastructure. Un échec peut être un contrôleur de disque serveur qui ne peut plus accéder à aucun disque, rendant les données inaccessibles. Ou l'échec pourrait être un commutateur réseau qui ne permet plus à deux ou plusieurs systèmes de communiquer. Dans ce contexte, un «point de défaillance unique» ou SPOF est une défaillance qui affecte négativement la disponibilité du service. Une infrastructure résiliente est une infrastructure sans SPOF.
«Évolutif» décrit la capacité des systèmes à gérer les pics de demande avec élégance. Il dicte également la facilité avec laquelle les modifications peuvent être apportées aux systèmes. Par exemple, ajouter un nouvel utilisateur, augmenter la capacité de stockage ou déplacer une infrastructure d'Amazon Web Services vers Google Cloud – ou même la déplacer en interne.
Dès que votre infrastructure s'étend au-delà d'un seul serveur, il existe de nombreuses options pour augmenter la sécurité, la résilience et l'évolutivité. Nous allons voir comment ces problèmes ont été résolus de manière traditionnelle et quelles nouvelles technologies sont disponibles pour changer le visage de l'informatique des grandes applications.
Sommaire
Obtenez plus de Linux!

(Crédit d'image: Future)
Vous aimez ce que vous lisez? Vous voulez plus de Linux et open source? Nous pouvons livrer, littéralement! Abonnez-vous au format Linux dès aujourd'hui à un prix avantageux. Vous pouvez obtenir des numéros d'impression, des éditions numériques ou pourquoi pas les deux? Nous livrons à votre porte dans le monde entier pour une simple cotisation annuelle. Alors rendez votre vie meilleure et plus facile, abonnez-vous maintenant!
Pour comprendre ce qui est possible aujourd'hui, il est utile d'examiner comment les projets technologiques sont traditionnellement mis en œuvre. Autrefois, c'est-à-dire il y a plus de 10 ans, les entreprises achetaient ou louaient du matériel pour exécuter tous les composants de leurs applications. Même des applications relativement simples, comme un site Web WordPress, ont plusieurs composants. Dans le cas de WordPress, une base de données MySQL est nécessaire avec un serveur Web, comme Apache, et un moyen de gérer le code PHP. Donc, ils construiraient un serveur, configureraient Apache, PHP et MySQL, installeraient WordPress et ils partiraient.
Dans l'ensemble, cela a fonctionné. Cela a fonctionné suffisamment bien pour qu'il y ait encore un grand nombre de serveurs configurés exactement de cette façon aujourd'hui. Mais ce n'était pas parfait, et deux des plus gros problèmes étaient la résilience et l'évolutivité.
Le manque de résilience signifiait que tout problème important sur le serveur entraînerait une perte de service. De toute évidence, une défaillance catastrophique ne signifierait pas de site Web, mais il n'y avait pas non plus de place pour effectuer la maintenance planifiée sans affecter le site Web. Même l'installation et l'activation d'une mise à jour de sécurité de routine pour Apache nécessiteraient une interruption de quelques secondes du site Web.
Le problème de la résilience a été largement résolu par la création de «clusters à haute disponibilité». Le principe était d'avoir deux serveurs exécutant le site Web, configurés de telle sorte que la défaillance de l'un ou l'autre n'entraîne pas la panne du site Web. Le service fourni était résilient même si les serveurs individuels ne l'étaient pas.
Nuages abstraits
Une partie de la puissance de Kubernetes est l'abstraction qu'elle offre. Du point de vue d'un développeur, ils développent l'application à exécuter dans un conteneur Docker. Docker ne se soucie pas de savoir s’il fonctionne sous Windows, Linux ou un autre système d’exploitation. Ce même conteneur Docker peut être extrait du MacBook du développeur et exécuté sous Kubernetes sans aucune modification.
L'installation de Kubernetes elle-même peut être une seule machine. Bien sûr, de nombreux avantages de Kubernetes ne seront pas disponibles: il n'y aura pas de mise à l'échelle automatique; il y a un seul point de défaillance évident, et ainsi de suite. Cependant, en tant que preuve de concept dans un environnement de test, cela fonctionne.
Une fois que vous êtes prêt pour la production, vous pouvez exécuter en interne ou sur un fournisseur de cloud tel que AWS ou Google Cloud. Les fournisseurs de cloud ont certains services intégrés qui aident à exécuter Kubernetes, mais aucun n'est une exigence stricte. Si vous souhaitez vous déplacer entre Google, Amazon et votre propre infrastructure, vous devez configurer Kubernetes et vous déplacer. Aucune de vos applications ne doit changer en aucune façon.
Et où est Linux? Kubernetes fonctionne sous Linux, mais le système d'exploitation est invisible pour les applications. Il s'agit d'une étape importante dans la maturité et l'utilisabilité des infrastructures informatiques.
L'effet Slashdot
Le problème d'évolutivité est un peu plus délicat. Disons que votre site WordPress reçoit 1 000 visiteurs par mois. Un jour, votre entreprise est mentionnée sur Radio 4 ou sur TV Breakfast. Du coup, vous obtenez plus d’un mois de visiteurs en 20 minutes. Nous avons tous entendu des histoires de sites Web qui se bloquent, et c'est généralement pourquoi: un manque d'évolutivité.
Les deux serveurs qui ont contribué à la résilience pouvaient gérer une charge de travail plus élevée qu’un seul serveur, mais cela reste limité. Vous paieriez pour deux serveurs 100% du temps et la plupart du temps, les deux fonctionnaient parfaitement. Il est probable qu'un seul puisse exécuter votre site. Ensuite, John Humphrys mentionne votre entreprise sur Today et vous aurez besoin de 10 serveurs pour gérer la charge, mais seulement pendant quelques heures.
Le cloud computing était la meilleure solution au problème de résilience et d'évolutivité. Configurez une ou deux instances de serveur – les petits serveurs qui exécutent vos applications – sur Amazon Web Services (AWS) ou Google Cloud, et si l'une des instances échouait pour une raison quelconque, elle serait automatiquement redémarrée. Configurez la mise à l'échelle automatique correctement et lorsque M. Humphrys provoque une augmentation rapide de la charge de travail sur vos instances de serveur Web, des instances de serveur supplémentaires sont automatiquement démarrées pour partager la charge de travail. Plus tard, à mesure que les intérêts diminuent, ces instances supplémentaires sont arrêtées et vous ne payez que ce que vous utilisez. Parfait… ou est-ce?
Bien que la solution cloud soit beaucoup plus flexible que le serveur autonome traditionnel, il existe encore des problèmes. La mise à jour de toutes les instances de cloud en cours d'exécution n'est pas simple. Le développement pour le cloud présente également des défis: l'ordinateur portable que vos développeurs utilisent peut être similaire à l'instance cloud, mais ce n'est pas la même chose. Si vous vous engagez sur AWS, la migration vers Google Cloud est une entreprise complexe. Et supposons, pour une raison quelconque, que vous ne vouliez tout simplement pas remettre votre informatique à Amazon, Google ou Microsoft?
Les conteneurs sont apparus comme un moyen d'envelopper les applications avec toutes leurs dépendances dans un package unique qui peut être exécuté n'importe où. Les conteneurs, tels que Docker, peuvent s'exécuter sur les ordinateurs portables de vos développeurs de la même manière qu'ils s'exécutent sur vos instances cloud, mais la gestion d'une flotte de conteneurs devient de plus en plus difficile à mesure que le nombre de conteneurs augmente.
La réponse est l'orchestration des conteneurs. Il s'agit d'un changement d'orientation important. Avant, nous nous assurions que nous avions suffisamment de serveurs, qu'ils soient physiques ou virtuels, pour nous assurer de pouvoir gérer la charge de travail. L'utilisation de la mise à l'échelle automatique des fournisseurs de cloud a aidé, mais nous étions toujours confrontés à des instances. Nous avons dû configurer les équilibreurs de charge, les pare-feu, le stockage des données et plus manuellement. Avec l'orchestration de conteneurs, tout cela (et bien plus encore) est pris en charge. Nous précisons les résultats dont nous avons besoin et nos outils d'orchestration de conteneurs répondent à nos exigences. Nous précisons ce que nous voulons faire, plutôt que la façon dont nous voulons le faire.
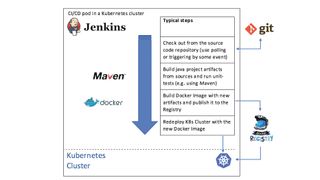
Devenez un Kubernete
Kubernetes (ku-ber-net-eez) est aujourd'hui le principal outil d'orchestration de conteneurs, et il vient de Google. Si quelqu'un sait comment gérer des infrastructures informatiques à grande échelle, Google le sait. L'origine de Kubernetes est Borg, un projet interne de Google qui est toujours utilisé pour exécuter la plupart des applications de Google, y compris son moteur de recherche, Gmail, Google Maps et plus encore. Borg était un secret jusqu'à ce que Google publie un article à ce sujet en 2015, mais le document montrait très clairement que Borg était la principale inspiration derrière Kubernetes.
Borg est un système qui gère les ressources de calcul dans les centres de données de Google et maintient les applications de Google, à la fois en production et autres, en cours d'exécution malgré une panne matérielle, l'épuisement des ressources ou d'autres problèmes qui auraient pu provoquer une panne. Pour ce faire, il surveille attentivement les milliers de nœuds qui composent une «cellule» Borg et les conteneurs qui s'y trouvent, et démarre ou arrête les conteneurs en fonction des problèmes ou des fluctuations de charge.
Kubernetes lui-même est né de l'initiative Google GIFEE («Google's Infrastructure For Everyone Else») et a été conçu pour être une version plus conviviale de Borg qui pourrait être utile en dehors de Google. Il a été donné à la Linux Foundation en 2015 grâce à la formation de la Cloud Native Computing Foundation (CNCF).
Kubernetes fournit un système par lequel vous «déclarez» vos applications et services conteneurisés et s'assure que vos applications s'exécutent conformément à ces déclarations. Si vos programmes nécessitent des ressources externes, telles que du stockage ou des équilibreurs de charge, Kubernetes peut les provisionner automatiquement. Il peut faire évoluer vos applications vers le haut ou vers le bas pour suivre les changements de charge, et peut même faire évoluer l'ensemble de votre cluster si nécessaire. Les composants de votre programme n'ont même pas besoin de savoir où ils s'exécutent: Kubernetes fournit des services de nommage internes aux applications afin qu'elles puissent se connecter à «wp_mysql» et être automatiquement connectées à la bonne ressource. »
Le résultat final est une plate-forme qui peut être utilisée pour exécuter vos applications sur n'importe quelle infrastructure, depuis une seule machine en passant par un rack de systèmes sur site jusqu'aux flottes basées sur le cloud de machines virtuelles fonctionnant sur n'importe quel fournisseur de cloud majeur, utilisant toutes les mêmes conteneurs et la configuration. Kubernetes est indépendant du fournisseur: exécutez-le où vous voulez.
Kubernetes est un outil puissant et nécessairement complexe. Avant d'entrer dans un aperçu, nous devons introduire certains termes utilisés dans Kubernetes. Les conteneurs exécutent des applications uniques, comme indiqué ci-dessus, et sont regroupés en modules. Un pod est un groupe de conteneurs étroitement liés qui sont déployés ensemble sur le même hôte et partagent certaines ressources. Les conteneurs d'un pod fonctionnent en équipe: ils exécutent des fonctions connexes, telles qu'un conteneur d'application et un conteneur de journalisation avec des paramètres spécifiques pour l'application.
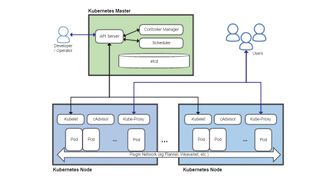
Quatre composants clés de Kubernetes sont le serveur API, le planificateur, le gestionnaire de contrôleur et une base de données de configuration distribuée appelée etcd. Le serveur API est au cœur de Kubernetes et agit comme point de terminaison principal pour toutes les demandes de gestion. Ceux-ci peuvent être générés par une variété de sources, y compris d'autres composants Kubernetes, tels que le planificateur, les administrateurs via la ligne de commande ou les tableaux de bord Web, et les applications conteneurisées elles-mêmes. Il valide les demandes et met à jour les données stockées dans etcd.
Le planificateur détermine sur quels nœuds les différents pods s'exécuteront, en tenant compte des contraintes telles que les besoins en ressources, les contraintes matérielles ou logicielles, la charge de travail, les délais et plus encore.
Le Controller Manager surveille l'état du cluster et essaiera de démarrer ou d'arrêter les pods si nécessaire, via le serveur API, pour amener le cluster à l'état souhaité. Il gère également certaines connexions internes et fonctionnalités de sécurité.
Chaque nœud exécute un processus Kubelet, qui communique avec le serveur API et gère les conteneurs – généralement à l'aide de Docker – et Kube-Proxy, qui gère le proxy réseau et l'équilibrage de charge au sein du cluster.
Le système de base de données distribuée etcd tire son nom du /etc dossier sur les systèmes Linux, qui est utilisé pour contenir les informations de configuration du système, plus le suffixe «d», souvent utilisé pour désigner un processus démon. Les objectifs de etcd sont de stocker des données de valeur-clé de manière distribuée, cohérente et tolérante aux pannes.
Le serveur API conserve toutes ses données d'état dans etcd et peut exécuter plusieurs instances simultanément. Le planificateur et le gestionnaire de contrôleur ne peuvent avoir qu'une seule instance active mais utilisent un système de bail pour déterminer quelle instance en cours d'exécution est le maître. Tout cela signifie que Kubernetes peut fonctionner comme un système hautement disponible sans aucun point de défaillance unique.
Mettre tous ensemble
Alors, comment utilisons-nous ces composants dans la pratique? Ce qui suit est un exemple de configuration d'un site Web WordPress à l'aide de Kubernetes. Si vous vouliez le faire pour de vrai, alors vous utiliseriez probablement une recette prédéfinie appelée un graphique de barre. Ils sont disponibles pour un certain nombre d'applications courantes, mais nous allons voir ici quelques-unes des étapes nécessaires pour obtenir un site WordPress opérationnel sur Kubernetes.
La première tâche consiste à définir un mot de passe pour MySQL:
kubectl crée un mysql-pass générique secret --from-literal = password = YOUR_PASSWORD
kubectl parlera au serveur API, qui validera la commande puis stockera le mot de passe dans etcd. Nos services sont définis dans des fichiers YAML, et maintenant nous avons besoin d'un stockage persistant pour la base de données MySQL.
apiVersion: v1
kind: PersistentVolumeClaim
métadonnées:
nom: mysql-pv-claim
Étiquettes:
application: wordpress
spec:
accessModes:
- ReadWriteOnce
Ressources:
demande:
stockage: 20Gi
La spécification doit être principalement explicite. Les champs de nom et d'étiquettes sont utilisés pour faire référence à ce stockage à partir d'autres parties de Kubernetes, dans ce cas notre conteneur WordPress.
Une fois que nous avons défini le stockage, nous pouvons définir une instance MySQL, en la pointant vers le stockage prédéfini. Ensuite, vous définissez la base de données elle-même. Nous donnons à cette base de données un nom et une étiquette pour une référence facile dans Kubernetes.
Maintenant, nous avons besoin d'un autre conteneur pour exécuter WordPress. Une partie de la spécification de déploiement de conteneur est:
type: Déploiement
métadonnées:
nom: wordpress
Étiquettes:
application: wordpress
spec:
stratégie:
type: recréer
Le type de stratégie «Recréer» signifie que si l'un des codes composant l'application change, les instances en cours d'exécution seront supprimées et recréées. D'autres options incluent la possibilité de faire défiler de nouvelles instances dans et de supprimer les instances existantes, une par une, permettant au service de continuer à s'exécuter pendant le déploiement d'une mise à jour. Enfin, nous déclarons un service pour WordPress lui-même, comprenant le code PHP et Apache. Une partie du fichier YAML déclarant ceci est:
métadonnées:
nom: wordpress
Étiquettes:
application: wordpress
spec:
ports:
- port: 80
sélecteur:
application: wordpress
niveau: frontend
type: LoadBalancer
Notez la dernière ligne, définissant le type de service comme LoadBalancer. Cela demande à Kubernetes de rendre le service disponible en dehors de Kubernetes. Sans cette ligne, il ne s'agirait que d'un service interne «Kubernetes uniquement». Et c'est tout. Kubernetes utilisera désormais ces fichiers YAML comme déclaration de ce qui est requis, et configurera les pods, les connexions, le stockage, etc. selon les besoins pour amener le cluster dans l'état «souhaité».
Cela n'a nécessairement été qu'un aperçu de haut niveau de Kubernetes, et de nombreux détails et fonctionnalités du système ont été omis. Nous avons passé sous silence la mise à l'échelle automatique (les pods et les nœuds qui composent un cluster), les tâches cron (démarrage des conteneurs selon un calendrier), Ingress (équilibrage de charge HTTP, réécriture et déchargement SSL), RBAC (contrôles d'accès basés sur les rôles) , les politiques de réseau (pare-feu) et bien plus encore. Kubernetes est extrêmement flexible et extrêmement puissant: pour toute nouvelle infrastructure informatique, il doit être un concurrent sérieux.
Ressources
Si vous ne connaissez pas Docker, commencez ici: https://docs.docker.com/get-started.
Il existe un didacticiel interactif sur le déploiement et la mise à l'échelle d'une application ici: https://kubernetes.io/docs/tutorials/kubernetes-basics.
Et consultez https://kubernetes.io/docs/setup/scratch pour savoir comment créer un cluster.
Vous pouvez jouer avec un cluster Kubernetes gratuit sur https://tryk8s.com.
Enfin, vous pouvez parcourir un long document technique avec un excellent aperçu de l'utilisation de Borg par Google et comment cela a influencé la conception de Kubernetes ici: https://storage.googleapis.com/pub-tools-public-publication-data/ pdf / 43438.pdf.
En savoir plus sur Tiger Computing.
Obtenez plus de Linux!

(Crédit d'image: Future)
Vous aimez ce que vous lisez? Vous voulez plus de Linux et open source? Nous pouvons livrer, littéralement! Abonnez-vous au format Linux dès aujourd'hui à un prix avantageux. Vous pouvez obtenir des numéros d'impression, des éditions numériques ou pourquoi pas les deux? Nous livrons à votre porte dans le monde entier pour une simple cotisation annuelle. Alors rendez votre vie meilleure et plus facile, abonnez-vous maintenant!






Commentaires
Laisser un commentaire