Accueil › Serveur minecraft › Le meilleur de arXiv.org pour l'IA, l'apprentissage automatique et l'apprentissage en profondeur – Octobre 2019
– Resoudre les problemes d’un serveur MineCraft
Serveur minecraft
Le meilleur de arXiv.org pour l'IA, l'apprentissage automatique et l'apprentissage en profondeur – Octobre 2019
– Resoudre les problemes d’un serveur MineCraft
Par Titanfall
, le
25 novembre 2019
-
7 minutes de lecture
Dans cette fonction mensuelle récurrente, nous filtrons les articles de recherche récents apparaissant sur le serveur de préimpression arXiv.org pour traiter de sujets captivants en matière d’intelligence artificielle, d’apprentissage automatique et d’apprentissage approfondi – issus de disciplines telles que la statistique, les mathématiques et l’informatique – et vous proposons un de "liste pour le mois dernier. Des chercheurs du monde entier contribuent à ce référentiel en guise de prélude au processus d'examen par les pairs en vue de sa publication dans des revues traditionnelles. arXiv contient un véritable trésor de méthodes d'apprentissage que vous pouvez utiliser un jour pour résoudre les problèmes de la science des données. Nous espérons vous faire gagner un peu de temps en sélectionnant les articles les plus prometteurs pour le spécialiste des données. Les articles énumérés ci-dessous représentent une fraction de tous les articles figurant sur le serveur de pré-impression. Ils sont énumérés dans aucun ordre particulier avec un lien vers chaque article avec un bref aperçu. Les articles particulièrement pertinents sont signalés par une icône représentant un "pouce levé". Considérez qu'il s'agit de documents de recherche académiques, généralement destinés aux étudiants des cycles supérieurs, aux post-doctorants et aux professionnels chevronnés. Ils contiennent généralement beaucoup de mathématiques, alors soyez prêts. Prendre plaisir!
NGBoost: boost de gradient naturel pour la prévision probabiliste
Le groupe Stanford ML présente le Natural Gradient Boosting (NGBoost), un algorithme qui apporte une capacité de prédiction probabiliste à l’amélioration du gradient de manière générique. L'estimation prédictive de l'incertitude est cruciale dans de nombreuses applications telles que les soins de santé et les prévisions météorologiques. La prédiction probabiliste, qui est l'approche dans laquelle le modèle génère une distribution de probabilité complète sur tout l'espace de résultats, est un moyen naturel de quantifier ces incertitudes. Les machines de renforcement de gradient ont largement réussi aux tâches de prédiction sur des données d'entrée structurées, mais une solution simple de renforcement pour la prédiction probabiliste de résultats réels n'a pas encore été trouvée. NGBoost est une approche de renforcement de gradient qui utilise le Gradient naturel résoudre les problèmes techniques qui rendent difficile la prévision générique probabiliste avec les méthodes existantes d’amélioration du gradient. Cette approche est modulaire en ce qui concerne le choix de l'apprenant de base, la distribution de probabilité et la règle de notation. Le document montre empiriquement, sur plusieurs ensembles de données de régression, que NGBoost fournit une performance prédictive compétitive à la fois des estimations de l’incertitude et des métriques traditionnelles.
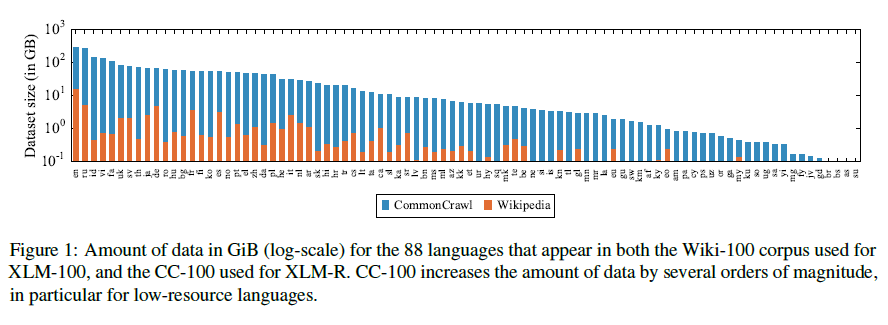
Apprentissage à l'échelle d'une représentation multilingue non supervisée
Cet article montre que la formation préalable de modèles linguistiques multilingues à grande échelle entraîne des gains de performance significatifs pour une large gamme de tâches de transfert multilingues. Les chercheurs de Facebook AI ont formé un modèle de langage masqué basé sur Transformer sur 100 langues, en utilisant plus de deux téraoctets de données CommonCrawl filtrées. Le modèle, baptisé XLM-R, surpasse considérablement le BERT multilingue (mBERT) sur une variété de critères de référence multilingues.
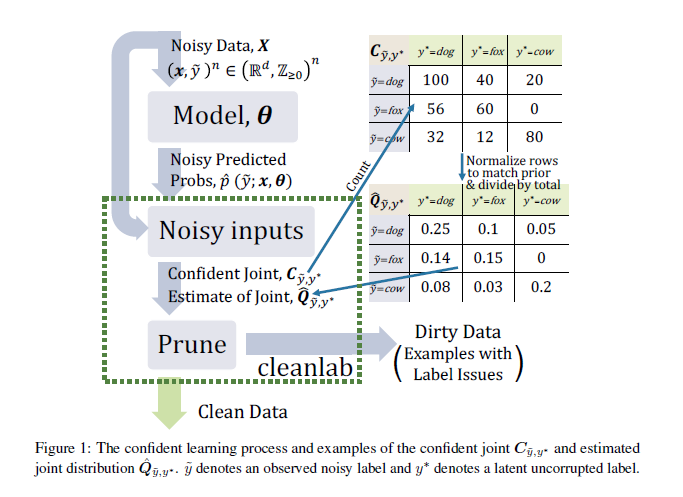
Apprentissage confiant: estimation de l'incertitude dans les étiquettes de jeux de données
L'apprentissage existe dans le contexte des données, mais les notions de confiance se concentrent généralement sur les prédictions du modèle et non sur la qualité des étiquettes. Confident Learning (CL) est apparu comme une approche de caractérisation, d’identification et d’apprentissage avec des étiquettes bruitées dans des ensembles de données, reposant sur les principes de la taille des données bruitées, comptant pour estimer le bruit et classant des exemples pour s’entraîner en toute confiance. Cet article généralise CL, en partant de l’hypothèse d’un processus de classification du bruit, pour estimer directement la distribution de joint entre les étiquettes bruitées (données) et les étiquettes non corrompues (inconnues). Ce code CL généralisé, de source ouverte appelée cleanlab, est parfaitement cohérent dans des conditions raisonnables et est expérimentalement performant sur ImageNet et l'ICRA, surpassant les approches récentes, par exemple. MentorNet, de 30% ou plus, lorsque le bruit des étiquettes n’est pas uniforme. cleanlab quantifie également le chevauchement des classes ontologiques et peut augmenter la précision du modèle (ResNet, par exemple) en fournissant des données claires pour la formation.
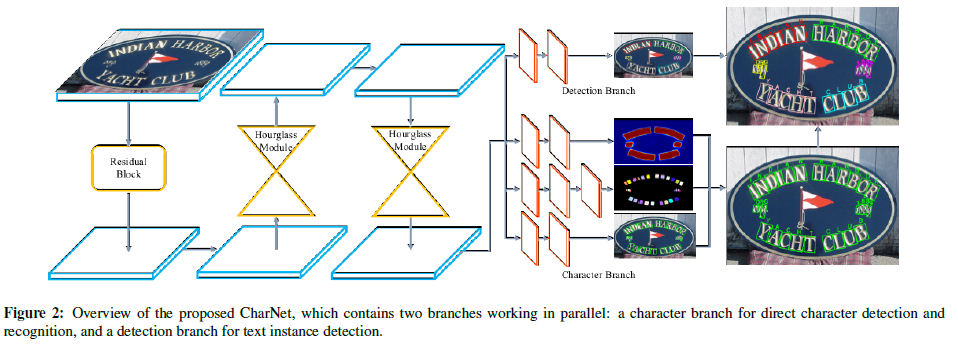
Réseaux de caractères convolutifs
Des progrès récents ont été accomplis dans l’élaboration d’un cadre unifié pour la détection et la reconnaissance de textes communs dans des images naturelles, mais les modèles conjoints existants reposaient pour la plupart sur un cadre en deux étapes, grâce à la mise en commun du retour sur investissement, susceptible de dégrader les performances en matière de reconnaissance. Ceci propose des réseaux de caractères convolutifs, appelés CharNet, qui est un modèle en une étape pouvant traiter deux tâches simultanément en un seul passage. CharNet génère directement des cadres de mots et de caractères, avec les libellés correspondants. La technologie utilise le caractère comme élément de base, ce qui nous permet de surmonter la principale difficulté des approches existantes qui tentaient d’optimiser la détection de texte conjointement avec une branche de reconnaissance basée sur RNN. En outre, le document développe une approche de détection de caractère itérative capable de transformer la capacité de détection de caractère apprise à partir de données synthétiques en images réelles. Ces améliorations techniques permettent de créer un modèle en une étape simple, compact et puissant, qui fonctionne de manière fiable sur un texte à orientation multiple et incurvé. Le code est disponible ICI.
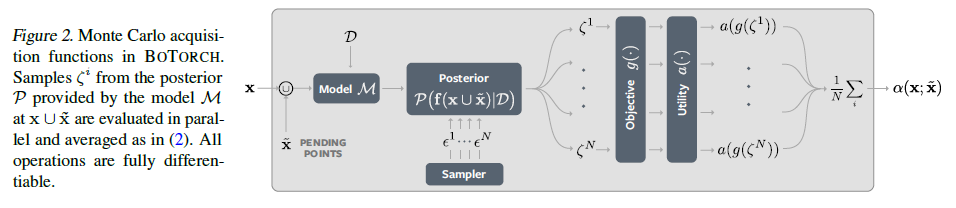
BoTorch: Optimisation bayésienne programmable dans PyTorch
L'optimisation bayésienne fournit une optimisation globale efficace en termes d'échantillonnage pour une large gamme d'applications, notamment l'apprentissage automatique, la chimie moléculaire et la conception expérimentale. Cet article présente BoTorch, un cadre de programmation moderne pour l'optimisation bayésienne. Grâce aux fonctions d’acquisition de Monte-Carlo (MC) et à la différenciation automatique, la conception modulaire de BoTorch facilite la spécification flexible et l’optimisation des modèles probabilistes écrits en PyTorch, simplifiant ainsi radicalement la mise en œuvre de nouvelles fonctions d’acquisition. L’approche MC est mise en pratique par une base algorithmique distincte qui exploite des distributions prédictives rapides et une accélération matérielle. Les expériences démontrent l'amélioration de l'efficacité des échantillons de BoTorch par rapport à d'autres bibliothèques populaires. BoTorch est open source et disponible à ICI.
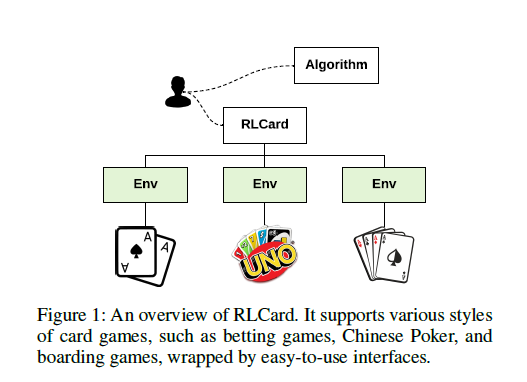
RLCard: Boîte à outils pour l'apprentissage par renforcement dans les jeux de cartes
RLCard est une boîte à outils open source pour la recherche sur l’apprentissage par renforcement dans les jeux de cartes. Il prend en charge divers environnements de carte avec des interfaces faciles à utiliser, notamment Blackjack, Leduc Hold’em, Texas Hold’em, UNO, Dou Dizhu et Mahjong. L'objectif de RLCard est de rapprocher l'apprentissage par renforcement et les jeux d'information imparfaits, et de faire avancer la recherche sur l'apprentissage par renforcement dans des domaines comportant de nombreux agents, un grand espace d'état et d'action et des récompenses rares. Dans cet article, nous fournissons un aperçu des composants clés de RLCard, une discussion des principes de conception, une brève introduction des interfaces et des évaluations complètes des environnements. Les codes et les documents sont disponibles ICI.
Inscrivez-vous à la newsletter gratuite insideBIGDATA.
Tutos Gameserver respecte votre vie privée et vos données personnelles
Nous utilisons des cookies sur notre site Web pour vous offrir l'expérience la plus pertinente en mémorisant vos préférences et vos visites répétées.
Les cookies sont utilisés pour la publicité personnalisée.
En cliquant sur "Accepter tout", vous consentez à l'utilisation de TOUS les cookies. Cependant, vous pouvez visiter "Paramètres des cookies" pour fournir un consentement contrôlé dans nos Mentions Légales.
Google et sites partenaires : Google’s Privacy & Terms site
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Durée
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.










Commentaires
Laisser un commentaire