
AI Startup Cerebras développe le processeur le plus puissant au monde – Bien choisir son serveur d impression
<div _ngcontent-c15 = "" innerhtml = "

L'architecte en chef de Cerebras, Sean Lie, tient le WSE (Wafer Scale Engine) – un modèle utilisant un … [+]
Avec une pléthore de jeunes entreprises de semi-conducteurs, d’entreprises de semi-conducteurs, d’universités, d’agences gouvernementales et même de fabricants d’appareils et de systèmes travaillant sur des puces pour intelligence artificielle, il est difficile de se démarquer. Cependant, une start-up appelée Cerebras a réussi à le faire. Hier, lors de la conférence Hot Chips à l'Université de Stanford, Cerebras a présenté une solution unique pour l'apprentissage en profondeur de l'IA, une merveille d'ingénierie.
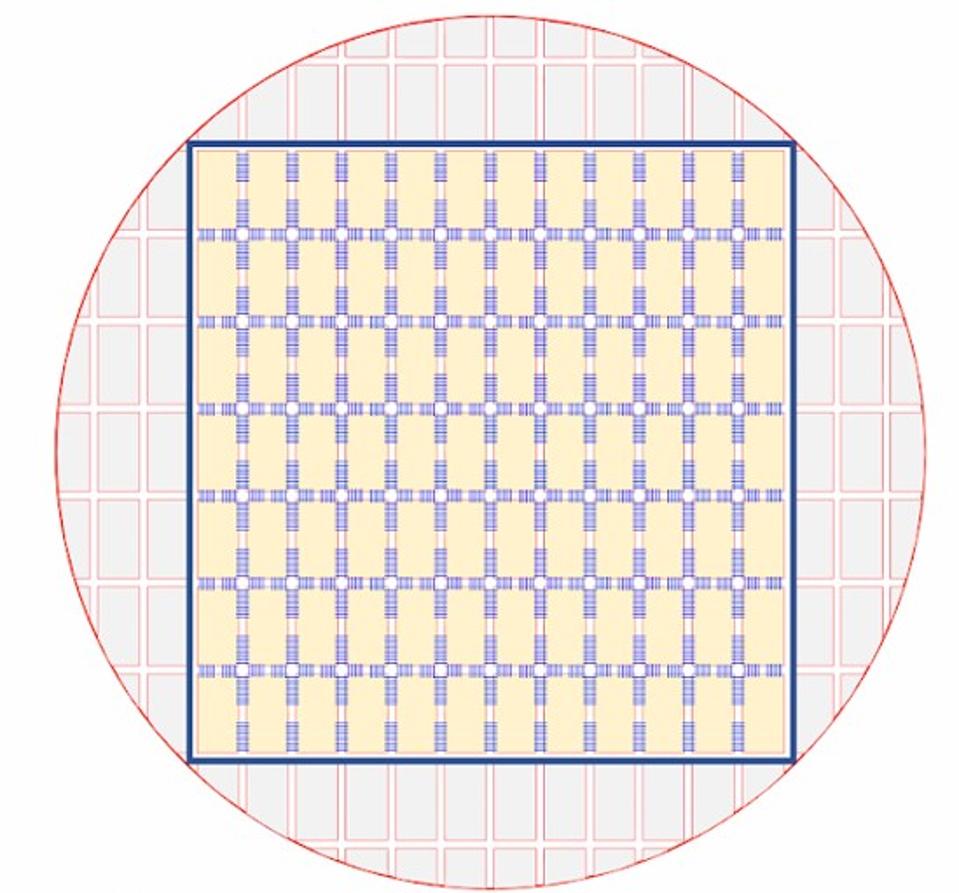
Le WSE comprend les tuiles de traitement connectées par la structure de communication Cerebras Swarm … [+]
Il y a tellement de choses qui rendent la solution Cerebras unique qu'il est difficile de savoir par où commencer. Cerebras a relevé de nombreux défis en matière de conception, de fabrication et d’emballage pour développer une solution à l’échelle de la tranche, appelée WSE (Scale Engine). Cela signifie que la conception utilise la totalité de l'espace utilisable de la tranche de silicium sous forme de puce ou de plate-forme unique. La plupart des puces sont fabriquées en plaçant 10 ou 100 exemplaires d’une puce sur une plaquette, puis en découpant celle-ci en puces individuelles. L'utilisation d'une plaquette entière en tant que puce unique a été tentée pour d'autres applications, mais a généralement été abandonnée pour des problèmes de coûts et de rendement. Une seule plaquette de 300 mm peut coûter 10 milliards de dollars à produire. Cependant, le moindre grain de poussière ou d'imperfection dans le traitement peut provoquer la défaillance d'une partie de la puce et souvent la défaillance de la totalité de la puce. Fabriquer une plaquette entière sans erreur est impossible, mais Cerebras a trouvé un moyen de la contourner. Cerebras WSE est constitué de 84 mosaïques de traitement, similaires aux puces individuelles, et chaque mosaïque possède des cœurs de processeur, une mémoire et des E / S redondants. Lorsqu'une partie d'une mosaïque tombe en panne, les fonctions supplémentaires sont remplacées par des outils logiciels, ce qui donne l'impression que la mosaïque fonctionne parfaitement. En conséquence, l’entreprise peut théoriquement obtenir un rendement de 100% de toutes les tuiles d’une plaquette et de toutes les plaquettes produites.
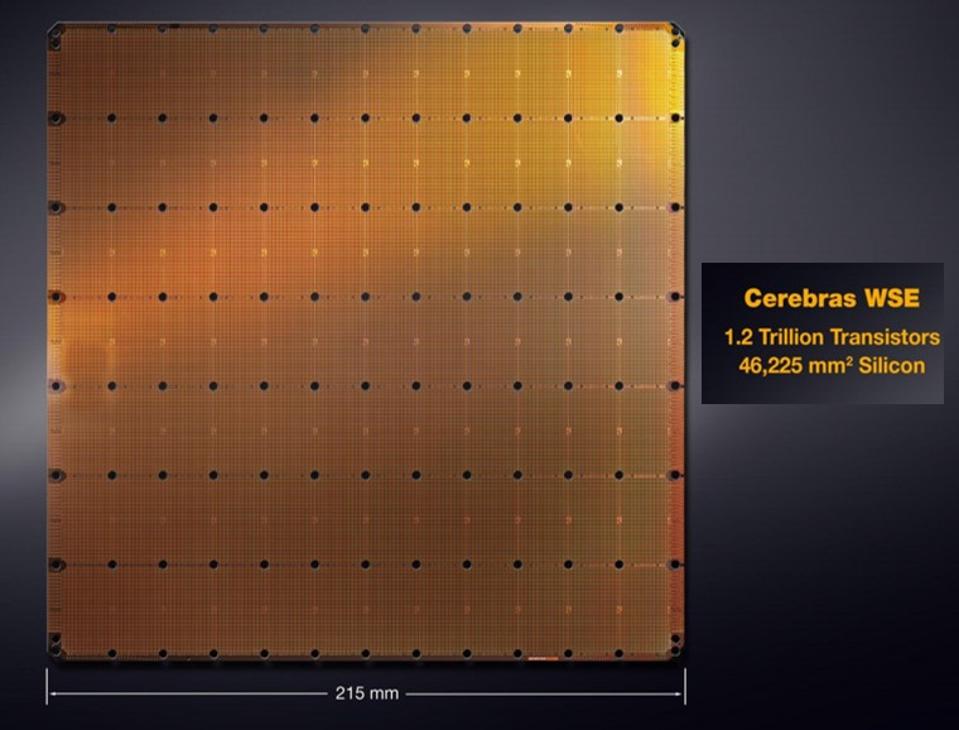
Le Cerebras WSE comprend 400 000 cœurs de processeur, 18 G de mémoire et un tissu à mailles de 25 pétabits
Cependant, la fabrication n'est qu'une partie de l'équation. Un autre problème est celui de l'alimentation en énergie et du refroidissement de toute une solution à l'échelle d'une tranche. Avec 400 000 cœurs de processeur programmables, 18 Go de mémoire et un tissu intégré capable de traiter 25 pétabits, le WSE comprend 1,2 billion de transistors dans 46 225 mm.2 de silicium immobilier (pour contraste, il est 56x plus grand que le plus grand GPU pour AI, qui est 815mm2). En outre, le WSE est évalué à 15 kW. Si vous parlez d'un système de batterie domestique, d'un panneau solaire ou d'un véhicule électrique, une discussion sur les kilowatts (kW) serait normale, mais pour une seule puce, c'est un ordre de grandeur supérieur à celui de toute puce jamais produite. Cela nécessitait une innovation dans le fonctionnement de l'appareil, la conception de la carte / du substrat et le système de refroidissement, juste pour gérer autant d'énergie et la chaleur qui en résultait.
Examinons chacune de ces innovations individuellement.
La première innovation concerne le fonctionnement du WSE. Avec une matrice de puces aussi grande, il serait inefficace, en termes de puissance et de latence, d'envoyer des données et des instructions sur la puce. En conséquence, les outils logiciels utilisés dans le développement du bloc de réseaux neuronaux rapprochent les tuiles de traitement en grappes, puis acheminent les données à travers la puce selon un chemin unique. Le chemin apparaît comme un labyrinthe aléatoire, mais il est optimisé pour utiliser la totalité de la puce tout en obtenant la latence la plus faible.
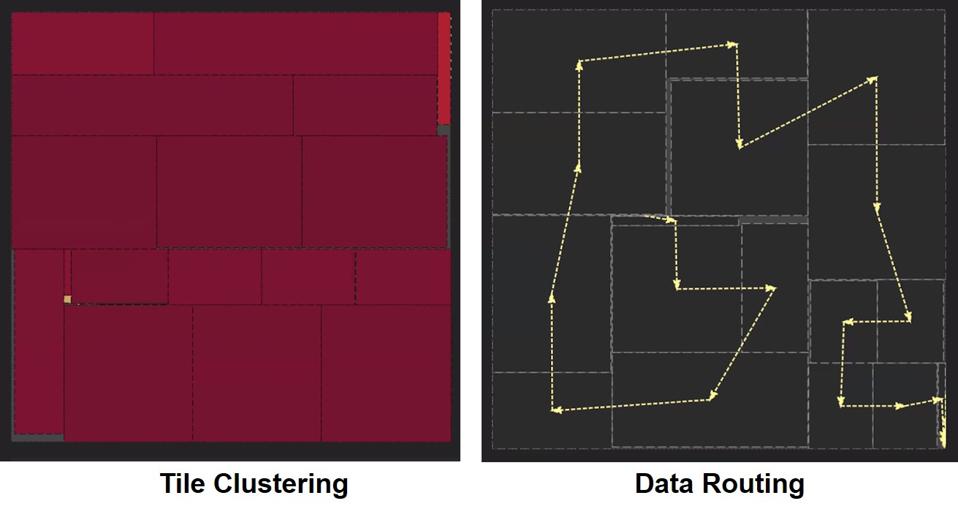
Dans le développement du réseau de neurones, les tuiles de traitement WSE sont regroupées avec un … [+]
La deuxième innovation est la conception du substrat pour répondre aux besoins en énergie. Contrairement aux autres processeurs basés sur des sockets, vous ne pouvez pas avoir un ou plusieurs connecteurs d’alimentation, car tout comme le routage des données, le routage de l’énergie sur une énorme puce serait inefficace et risquerait d’être dommageable en créant des points chauds. La puissance doit être appliquée uniformément à chacune des tuiles de traitement sur la tranche. Cerebras a atteint cet objectif en appliquant de la puissance à chaque dalle à travers un substrat spécial plutôt que par des motifs de routage sur le substrat. Considérez-le comme ayant des broches d'alimentation individuelles pour chaque tuile de processeur.
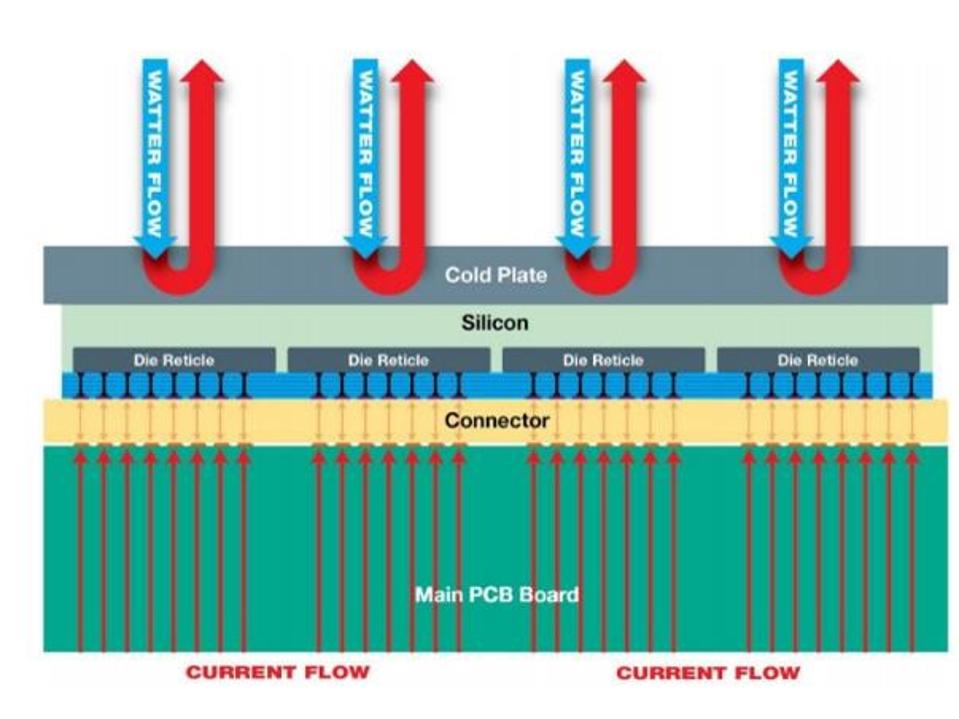
La grande taille du Cerebras WSE nécessite une alimentation et un refroidissement uniformes.
La troisième innovation est le refroidissement. Toute la puce de 15 kW doit être refroidie, et le refroidissement par liquide est la seule option viable. Cependant, si vous faites couler de l'eau ou un autre liquide de refroidissement sur la puce, le flux deviendra chaud au moment où il atteindra le côté opposé de la puce, endommageant éventuellement la puce. Cerebras a surmonté ce défi en proposant une solution de refroidissement comportant plusieurs zones, chaque zone disposant de ses propres ports d’eau d’entrée et de sortie. Ainsi, au lieu d’avoir un radiateur, plusieurs radiateurs refroidissent la puce.
En plus de ces innovations techniques, la société développe de nouveaux noyaux programmables d’algèbre linéaire allégés (SLAC) optimisés pour le traitement de l’intelligence artificielle. Le SLAC ignore toute fonction qui se multiplie par zéro, ce qui peut considérablement accélérer la multiplication des matrices dans le processus d'apprentissage en profondeur tout en réduisant la consommation d'énergie. La société a également réduit la pile de mémoire en éliminant le cache et en plaçant de grandes quantités de mémoire haute vitesse (18 Go de mémoire SRAM) à proximité des cœurs de traitement. Tout cela est lié à ce que la société appelle le tissu de communication Swarm, un tissu maillé 2D avec une largeur de bande de 25 pétabits conçue pour s'adapter entre les cœurs du processeur et les carreaux, y compris ce qui serait normalement une zone de découpe à la matrice sur la tranche.
Toutes ces innovations devront être mises en œuvre dans un châssis, ce dont Cerebras ne discute pas pour le moment. Toutefois, la société a indiqué que davantage d’informations seraient disponibles d’ici la fin de l’année. Notez que la solution Cerebras est conçue uniquement pour le traitement de l'IA. Par conséquent, WSE devra être connecté à un ou plusieurs processeurs hôtes. Mais le résultat est toujours un serveur unique avec des milliers d'accélérateurs d'intelligence artificielle tous regroupés dans une seule puce. Bien que les détails du logiciel soient limités, la société a indiqué que le WSE prend en charge TensorFlow et d’autres infrastructures logicielles courantes.
De par sa conception, la plate-forme Cerebras WSE présente des avantages en termes de latence, de bande passante, d’efficacité de traitement et de taille. Selon Cerebras, le WSE est 56,7 fois plus volumineux que le plus grand GPU, 3 000 fois plus de mémoire vive, de 10 000 fois plus de bande passante mémoire et s’adapte à 1/50.th de l'espace d'une configuration de centre de données traditionnel avec des milliers de nœuds de serveur. La société n’a pas évoqué la disponibilité de la plate-forme ni son coût estimé.
Autre élément qui distingue Cerebras du lot, l’entreprise se concentre sur la formation en profondeur. Il existe deux formes de traitement de l'IA. L'un est la formation de réseaux de neurones artificiels, réalisée à l'aide d'une variété de techniques d'apprentissage en profondeur et de cadres logiciels. L'autre forme de traitement de l'IA est l'inférence, qui utilise un réseau de neurones entraîné pour prendre une décision ou une décision. La plupart des entreprises se concentrent sur le traitement des inférences, car il représentera la grande majorité du traitement des IA. Bon nombre des nouveaux entrants d'IA déclarent faire les deux. Bien que l'entraînement et l'inférence soient possibles, il existe un compromis entre performance et efficacité. Les solutions les plus efficaces viseront généralement l’un ou l’autre.
Comme beaucoup de nouvelles entreprises de semi-conducteurs, Cerebras compte de nombreux entrepreneurs en série et experts du secteur qui savent ce qu'il faut pour réussir. Cependant, la société a choisi une voie technique complètement différente de celle de ses pairs. Comme Tirias Research l’a déjà indiqué, l’intelligence artificielle laisse beaucoup de place à différentes plates-formes car il n’ya pas deux charges de travail identiques. Nous nous félicitons du risque audacieux que Cerebras prend en matière de conception pour pousser les technologies au-delà de ce que nous pensions être les limites. La solution Cerebras est unique et semble bien adaptée à la formation de très grands ensembles de données. Toutefois, les coûts et les ressources du centre de données, en particulier l’énergie, devront être pris en compte. Avec la plate-forme actuelle, seules les plus grandes sociétés Internet, les fournisseurs de services cloud et les entreprises clientes sont susceptibles d'être des clients potentiels.
Veuillez continuer à rechercher plus d'informations auprès de Tirias Research dans notre couverture continue de l'intelligence artificielle pendant que nous discutons des entreprises, de la technologie et des applications qui façonnent l'évolution de l'IA.
L'auteur et les membres du personnel de TIRIAS Research ne détiennent aucune participation dans les sociétés mentionnées. TIRIAS Research suit et consulte les entreprises de l’écosystème électronique, des semi-conducteurs aux systèmes, en passant par les capteurs et le cloud. Les membres de l'équipe de recherche TIRIAS n'ont pas consulté Cerebras, mais sont en contact avec des entités de la communauté de l'IA.
">
L'architecte en chef de Cerebras, Sean Lie, tient le WSE (Wafer Scale Engine) – un modèle utilisant un … [+]
Avec une pléthore de jeunes entreprises de semi-conducteurs, d’entreprises de semi-conducteurs, d’universités, d’agences gouvernementales et même de fabricants d’appareils et de systèmes travaillant sur des puces pour intelligence artificielle, il est difficile de se démarquer. Cependant, une start-up appelée Cerebras a réussi à le faire. Hier, lors de la conférence Hot Chips à l'Université de Stanford, Cerebras a présenté une solution unique pour l'apprentissage en profondeur de l'IA, une merveille d'ingénierie.
Le WSE comprend des tuiles de traitement connectées par la structure de communication Cerebras Swarm à travers … [+]
Il y a tellement de choses qui rendent la solution Cerebras unique qu'il est difficile de savoir par où commencer. Cerebras a relevé de nombreux défis en matière de conception, de fabrication et d’emballage pour développer une solution à l’échelle de la tranche, appelée WSE (Scale Engine). Cela signifie que la conception utilise la totalité de l'espace utilisable de la tranche de silicium sous forme de puce ou de plate-forme unique. La plupart des puces sont fabriquées en plaçant 10 ou 100 exemplaires d’une puce sur une plaquette, puis en découpant celle-ci en puces individuelles. L'utilisation d'une plaquette entière en tant que puce unique a été tentée pour d'autres applications, mais a généralement été abandonnée pour des problèmes de coûts et de rendement. Une seule plaquette de 300 mm peut coûter 10 milliards de dollars à produire. Cependant, le moindre grain de poussière ou d'imperfection dans le traitement peut provoquer la défaillance d'une partie de la puce et souvent la défaillance de la totalité de la puce. Fabriquer une plaquette entière sans erreur est impossible, mais Cerebras a trouvé un moyen de la contourner. Cerebras WSE est constitué de 84 mosaïques de traitement, similaires aux puces individuelles, et chaque mosaïque possède des cœurs de processeur, une mémoire et des E / S redondants. Lorsqu'une partie d'une mosaïque tombe en panne, les fonctions supplémentaires sont remplacées par des outils logiciels, ce qui donne l'impression que la mosaïque fonctionne parfaitement. En conséquence, l’entreprise peut théoriquement obtenir un rendement de 100% de toutes les tuiles d’une plaquette et de toutes les plaquettes produites.
Le Cerebras WSE comprend 400 000 cœurs de processeur, 18 G de mémoire et un tissu à mailles de 25 pétabits
Cependant, la fabrication n'est qu'une partie de l'équation. Un autre problème est celui de l'alimentation en énergie et du refroidissement de toute une solution à l'échelle d'une tranche. Avec 400 000 cœurs de processeur programmables, 18 Go de mémoire et un tissu intégré capable de traiter 25 pétabits, le WSE comprend 1,2 billion de transistors dans 46 225 mm.2 de silicium immobilier (pour contraste, il est 56x plus grand que le plus grand GPU pour AI, qui est 815mm2). En outre, le WSE est évalué à 15 kW. Si vous parlez d'un système de batterie domestique, d'un panneau solaire ou d'un véhicule électrique, une discussion sur les kilowatts (kW) serait normale, mais pour une seule puce, c'est un ordre de grandeur supérieur à celui de toute puce jamais produite. Cela nécessitait une innovation dans le fonctionnement de l'appareil, la conception de la carte / du substrat et le système de refroidissement, juste pour gérer autant d'énergie et la chaleur qui en résultait.
Examinons chacune de ces innovations individuellement.
La première innovation concerne le fonctionnement du WSE. Avec une matrice de puces aussi grande, il serait inefficace, en termes de puissance et de latence, d'envoyer des données et des instructions sur la puce. En conséquence, les outils logiciels utilisés dans le développement du bloc de réseaux neuronaux rapprochent les tuiles de traitement en grappes, puis acheminent les données à travers la puce selon un chemin unique. Le chemin apparaît comme un labyrinthe aléatoire, mais il est optimisé pour utiliser la totalité de la puce tout en obtenant la latence la plus faible.
Dans le développement du réseau de neurones, les tuiles de traitement WSE sont regroupées avec un … [+]
La deuxième innovation est la conception du substrat pour répondre aux besoins en énergie. Contrairement aux autres processeurs basés sur des sockets, vous ne pouvez pas avoir un ou plusieurs connecteurs d’alimentation, car tout comme le routage des données, le routage de l’énergie sur une énorme puce serait inefficace et risquerait d’être dommageable en créant des points chauds. La puissance doit être appliquée uniformément à chacune des tuiles de traitement sur la tranche. Cerebras a atteint cet objectif en appliquant de la puissance à chaque dalle à travers un substrat spécial plutôt que par des motifs de routage sur le substrat. Considérez-le comme ayant des broches d'alimentation individuelles pour chaque tuile de processeur.
La grande taille du Cerebras WSE nécessite une alimentation et un refroidissement uniformes.
La troisième innovation est le refroidissement. Toute la puce de 15 kW doit être refroidie, et le refroidissement par liquide est la seule option viable. Cependant, si vous faites couler de l'eau ou un autre liquide de refroidissement sur la puce, le flux deviendra chaud au moment où il atteindra le côté opposé de la puce, endommageant éventuellement la puce. Cerebras a surmonté ce défi en proposant une solution de refroidissement comportant plusieurs zones, chaque zone disposant de ses propres ports d’eau d’entrée et de sortie. Ainsi, au lieu d’avoir un radiateur, plusieurs radiateurs refroidissent la puce.
En plus de ces innovations techniques, la société développe de nouveaux noyaux programmables d’algèbre linéaire allégés (SLAC) optimisés pour le traitement de l’intelligence artificielle. Le SLAC ignore toute fonction qui se multiplie par zéro, ce qui peut considérablement accélérer la multiplication des matrices dans le processus d'apprentissage en profondeur tout en réduisant la consommation d'énergie. La société a également réduit la pile de mémoire en éliminant le cache et en plaçant de grandes quantités de mémoire haute vitesse (18 Go de mémoire SRAM) à proximité des cœurs de traitement. Tout cela est lié à ce que la société appelle le tissu de communication Swarm, un tissu maillé 2D avec une largeur de bande de 25 pétabits conçue pour s'adapter entre les cœurs du processeur et les carreaux, y compris ce qui serait normalement une zone de découpe à la matrice sur la tranche.
Toutes ces innovations devront être mises en œuvre dans un châssis, ce dont Cerebras ne discute pas pour le moment. Toutefois, la société a indiqué que davantage d’informations seraient disponibles d’ici la fin de l’année. Notez que la solution Cerebras est conçue uniquement pour le traitement de l'IA. Par conséquent, WSE devra être connecté à un ou plusieurs processeurs hôtes. Mais le résultat est toujours un serveur unique avec des milliers d'accélérateurs d'intelligence artificielle tous regroupés dans une seule puce. Bien que les détails du logiciel soient limités, la société a indiqué que le WSE prend en charge TensorFlow et d’autres infrastructures logicielles courantes.
De par sa conception, la plate-forme Cerebras WSE présente des avantages en termes de latence, de bande passante, d’efficacité de traitement et de taille. Selon Cerebras, le WSE est 56,7 fois plus volumineux que le plus grand GPU, 3 000 fois plus de mémoire vive, de 10 000 fois plus de bande passante mémoire et s’adapte à 1/50.th de l'espace d'une configuration de centre de données traditionnel avec des milliers de nœuds de serveur. La société n’a pas évoqué la disponibilité de la plate-forme ni son coût estimé.
Autre élément qui distingue Cerebras du lot, l’entreprise se concentre sur la formation en profondeur. Il existe deux formes de traitement de l'IA. L'un est la formation de réseaux de neurones artificiels, réalisée à l'aide d'une variété de techniques d'apprentissage en profondeur et de cadres logiciels. L'autre forme de traitement de l'IA est l'inférence, qui utilise un réseau de neurones entraîné pour prendre une décision ou une décision. La plupart des entreprises se concentrent sur le traitement des inférences, car il représentera la grande majorité du traitement des IA. Bon nombre des nouveaux entrants d'IA déclarent faire les deux. Bien que l'entraînement et l'inférence soient possibles, il existe un compromis entre performance et efficacité. Les solutions les plus efficaces viseront généralement l’un ou l’autre.
Comme beaucoup de nouvelles entreprises de semi-conducteurs, Cerebras compte de nombreux entrepreneurs en série et experts du secteur qui savent ce qu'il faut pour réussir. Cependant, la société a choisi une voie technique complètement différente de celle de ses pairs. Comme Tirias Research l’a déjà indiqué, l’intelligence artificielle laisse beaucoup de place à différentes plates-formes car il n’ya pas deux charges de travail identiques. Nous nous félicitons du risque audacieux que Cerebras prend en matière de conception pour pousser les technologies au-delà de ce que nous pensions être les limites. La solution Cerebras est unique et semble bien adaptée à la formation de très grands ensembles de données. Toutefois, les coûts et les ressources du centre de données, en particulier l’énergie, devront être pris en compte. Avec la plate-forme actuelle, seules les plus grandes sociétés Internet, les fournisseurs de services cloud et les entreprises clientes sont susceptibles d'être des clients potentiels.
Veuillez continuer à rechercher plus d'informations auprès de Tirias Research dans notre couverture continue de l'intelligence artificielle pendant que nous discutons des entreprises, de la technologie et des applications qui façonnent l'évolution de l'IA.
L'auteur et les membres du personnel de TIRIAS Research ne détiennent aucune participation dans les sociétés mentionnées. TIRIAS Research suit et consulte les entreprises de l’écosystème électronique, des semi-conducteurs aux systèmes, en passant par les capteurs et le cloud. Les membres de l'équipe de recherche TIRIAS n'ont pas consulté Cerebras, mais sont en contact avec des entités de la communauté de l'IA.






Commentaires
Laisser un commentaire