
Pôle informatique – Wikipedia – Bien choisir son serveur d impression


UNE cluster informatique est un ensemble d’ordinateurs mal connectés ou étroitement connectés qui fonctionnent ensemble, de sorte qu’à de nombreux égards, ils peuvent être considérés comme un seul système. Contrairement aux ordinateurs en grille, chaque groupe de nœuds d'ordinateurs est configuré pour effectuer la même tâche, contrôlée et planifiée par logiciel.
Les composants d’une grappe sont généralement connectés les uns aux autres via des réseaux locaux rapides, chacun nœud (ordinateur utilisé en tant que serveur) exécutant sa propre instance d'un système d'exploitation. Dans la plupart des cas, tous les nœuds utilisent le même matériel[1][[meilleure source nécessaire] et le même système d’exploitation, bien que dans certaines configurations (par exemple, l’utilisation de ressources OSCAR (Open Source Cluster Application Resources)), différents systèmes d’exploitation puissent être utilisés sur chaque ordinateur ou différents matériels.[2]
Les clusters sont généralement déployés pour améliorer les performances et la disponibilité par rapport à un seul ordinateur, tout en étant généralement beaucoup plus économiques que des ordinateurs uniques d'une vitesse ou d'une disponibilité comparable.[3]
Les grappes d'ordinateurs sont apparues à la suite de la convergence d'un certain nombre de tendances informatiques, notamment la disponibilité de microprocesseurs à faible coût, de réseaux haut débit et de logiciels pour l'informatique distribuée hautes performances.[[citation requise] Leur applicabilité et leur déploiement sont très variés, allant des grappes de petites entreprises avec quelques nœuds à des supercalculateurs parmi les plus rapides au monde, tels que Sequoia d’IBM.[4] Avant l’avènement des clusters, des ordinateurs centraux tolérants aux pannes avec une redondance modulaire étaient utilisés. mais le coût initial plus bas des grappes et la rapidité accrue de la structure du réseau ont favorisé l'adoption de grappes. Contrairement aux systèmes mainframe hautement fiables, les grappes sont moins coûteuses à déployer, mais la gestion des erreurs est également plus complexe, car les modes d'erreur des grappes ne sont pas opaques pour les programmes en cours d'exécution.[5]
Sommaire
Concepts de base[[modifier]

Le désir d'obtenir plus de puissance de calcul et une meilleure fiabilité en orchestrant un certain nombre d'ordinateurs commerciaux disponibles dans le commerce à faible coût a donné naissance à une variété d'architectures et de configurations.
L’approche de regroupement d’ordinateurs connecte généralement (mais pas toujours) un certain nombre de nœuds informatiques facilement disponibles (par exemple, des ordinateurs personnels utilisés en tant que serveurs) via un réseau local rapide.[6] Les activités des noeuds informatiques sont orchestrées par un "middleware de mise en cluster", une couche logicielle située au-dessus des noeuds et permettant aux utilisateurs de traiter le cluster comme une unité informatique cohérente, par exemple. via un concept d'image système unique.[6]
Le regroupement d'ordinateurs repose sur une approche de gestion centralisée qui rend les nœuds disponibles sous forme de serveurs partagés orchestrés. Il se distingue d’autres approches telles que l’informatique peer to peer ou la grille qui utilise également de nombreux nœuds, mais avec une nature beaucoup plus distribuée.[6]
Un groupe d'ordinateurs peut être un simple système à deux nœuds qui ne fait que connecter deux ordinateurs personnels ou un superordinateur très rapide. Une approche de base pour la construction d'un cluster est celle d'un cluster Beowulf qui peut être construit avec quelques ordinateurs personnels pour produire une alternative rentable au calcul traditionnel haute performance. L'un des premiers projets montrant la viabilité du concept était l'ordinateur de soupe en pierre à 133 nœuds.[7] Les développeurs ont utilisé Linux, la boîte à outils Parallel Virtual Machine et la bibliothèque Message Passing Interface pour obtenir des performances élevées à un coût relativement bas.[8]
Même si un cluster peut ne comprendre que quelques ordinateurs personnels connectés par un simple réseau, son architecture peut également être utilisée pour atteindre des niveaux de performances très élevés. La liste semestrielle des 500 supercalculateurs les plus rapides de l'organisation TOP500 comprend souvent de nombreux clusters, par exemple. La machine la plus rapide du monde en 2011 était l'ordinateur K, doté d'une mémoire distribuée et d'une architecture en cluster.[9]
Histoire[[modifier]

Greg Pfister a déclaré que les grappes n’étaient pas inventées par un fournisseur spécifique, mais par des clients qui ne pouvaient pas placer tout leur travail sur un seul ordinateur ou qui avaient besoin d’une sauvegarde.[10] Pfister estime que cette date date des années 1960. Gene Amdahl d'IBM, qui a publié en 1967 ce qui a été considéré comme le principal document sur le traitement parallèle: la loi d'Amdahl, a sans doute été à l'origine de l'ingénierie formelle de l'informatique en grappes en tant que moyen de travail parallèle de toute sorte.
L’histoire des premiers clusters d’ordinateurs est plus ou moins directement liée à celle des premiers réseaux, l’une des principales motivations du développement d’un réseau étant de relier les ressources informatiques, créant ainsi un cluster de facto.
Le premier système de production conçu comme un cluster était le Burroughs B5700 au milieu des années 1960. Cela a permis à quatre ordinateurs, dotés chacun d'un ou deux processeurs, d'être étroitement couplés à un sous-système de stockage sur disque commun afin de répartir la charge de travail. Contrairement aux systèmes multiprocesseurs standard, chaque ordinateur peut être redémarré sans perturber le fonctionnement général.
Le premier produit commercial de clustering à couplage lâche a été le système ARC («Attached Resource Computer») de Datapoint Corporation, développé en 1977 et utilisant ARCnet comme interface de cluster. Le clustering en tant que tel n'a pas vraiment décollé avant que Digital Equipment Corporation ne commercialise son produit VAXcluster en 1984 pour le système d'exploitation VAX / VMS (maintenant appelé OpenVMS). Les produits ARC et VAXcluster ont non seulement pris en charge l’informatique parallèle, mais également les systèmes de fichiers partagés et les périphériques. L'idée était de fournir les avantages du traitement en parallèle, tout en maintenant la fiabilité et l'unicité des données. Deux autres premiers groupes commerciaux remarquables étaient les Tandem himalayen (un produit à haute disponibilité circa 1994) et le Sysplex parallèle IBM S / 390 (également vers 1994, principalement à des fins professionnelles).
Dans le même laps de temps, alors que les grappes d’ordinateurs utilisaient le parallélisme en dehors de l’ordinateur sur un réseau de produits de base, les supercalculateurs ont commencé à les utiliser au sein du même ordinateur. Suite au succès rencontré par le CDC 6600 en 1964, le Cray 1 fut livré en 1976 et introduisit le parallélisme interne via le traitement vectoriel.[11] Alors que les premiers superordinateurs excluaient les grappes et utilisaient la mémoire partagée, certains des supercalculateurs les plus rapides (l'ordinateur K par exemple) s'appuyaient sur des architectures de grappes.
Attributs des clusters[[modifier]
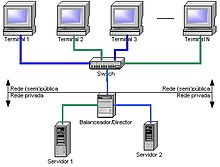
Les grappes d'ordinateurs peuvent être configurées à des fins différentes, allant de besoins commerciaux généraux tels que la prise en charge de services Web à des calculs scientifiques exigeants en calcul. Dans les deux cas, le cluster peut utiliser une approche de haute disponibilité. Notez que les attributs décrits ci-dessous ne sont pas exclusifs et qu'un "groupe d'ordinateurs" peut également utiliser une approche de haute disponibilité, etc.
Les clusters "à équilibrage de charge" sont des configurations dans lesquelles les nœuds de cluster partagent la charge de travail informatique afin d'améliorer les performances globales. Par exemple, un cluster de serveurs Web peut affecter différentes requêtes à différents nœuds, de sorte que le temps de réponse global sera optimisé.[12] Cependant, les approches en matière d'équilibrage de charge peuvent différer considérablement d'une application à une autre, par exemple. une grappe hautes performances utilisée pour des calculs scientifiques équilibrerait la charge avec différents algorithmes d'une grappe de serveurs Web pouvant simplement utiliser une simple méthode de répétition alternée en affectant chaque nouvelle demande à un nœud différent.[12]
Les clusters d’ordinateurs sont utilisés à des fins de calcul intensif, plutôt que de gérer des opérations orientées IO telles que des services Web ou des bases de données.[13] Par exemple, un groupe d’ordinateurs peut prendre en charge des simulations informatiques des accidents de la route ou des conditions météorologiques. Les grappes d'ordinateurs très étroitement couplées sont conçues pour des travaux pouvant s'approcher du "calcul intensif".
Les "clusters à haute disponibilité" (également appelés clusters de basculement ou HA) améliorent la disponibilité de l'approche cluster. Ils fonctionnent avec des nœuds redondants, qui sont ensuite utilisés pour fournir un service en cas de défaillance des composants du système. Les implémentations de cluster haute disponibilité tentent d'utiliser la redondance des composants du cluster pour éliminer les points de défaillance uniques. Il existe des implémentations commerciales de clusters à haute disponibilité pour de nombreux systèmes d'exploitation. Le projet Linux-HA est un package logiciel libre HA couramment utilisé pour le système d'exploitation Linux.
Avantages[[modifier]
Les clusters sont principalement conçus pour la performance, mais les installations sont basées sur de nombreux autres facteurs. Tolérance aux pannes (la possibilité pour un système de continuer à travailler avec un nœud défaillant) permet l’évolutivité et, dans les situations les plus performantes, des routines de maintenance peu fréquentes, la consolidation des ressources (par exemple, RAID) et la gestion centralisée. Les avantages sont notamment de permettre la récupération des données en cas de sinistre, le traitement parallèle des données et une capacité de traitement élevée.[14][15]
En termes d'évolutivité, les clusters fournissent cela dans leur capacité à ajouter des nœuds horizontalement. Cela signifie que davantage d'ordinateurs peuvent être ajoutés au cluster afin d'améliorer ses performances, sa redondance et sa tolérance aux pannes. Cela peut constituer une solution peu coûteuse pour un cluster plus performant par rapport à la mise à l'échelle d'un seul nœud du cluster. Cette propriété des clusters d’ordinateurs peut permettre l’exécution de charges de calcul plus importantes par un plus grand nombre d’ordinateurs peu performants.
Lors de l'ajout d'un nouveau nœud à un cluster, la fiabilité augmente car il n'est pas nécessaire de démonter l'intégralité du cluster. Un seul nœud peut être mis hors service à des fins de maintenance, tandis que le reste du cluster assume la charge de ce nœud individuel.
Si vous avez un grand nombre d'ordinateurs en cluster, cela se prête parfaitement à l'utilisation de systèmes de fichiers distribués et de RAID, qui peuvent tous deux augmenter la fiabilité et la vitesse d'un cluster.
Conception et configuration[[modifier]
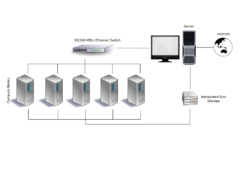
L'un des problèmes de la conception d'un cluster est le degré de couplage étroit des nœuds individuels. Par exemple, un travail sur un seul ordinateur peut nécessiter des communications fréquentes entre les nœuds: cela signifie que le cluster partage un réseau dédié, est densément situé et possède probablement des nœuds homogènes. L'autre extrême est lorsqu'un travail informatique utilise un ou plusieurs noeuds et nécessite peu ou pas de communication inter-noeuds, à l'approche du calcul en grille.
Dans un cluster Beowulf, les programmes d'application ne voient jamais les nœuds de calcul (également appelés ordinateurs esclaves), mais n'interagissent qu'avec le "maître", qui est un ordinateur spécifique chargé de la planification et de la gestion des esclaves.[13] Dans une implémentation typique, le maître possède deux interfaces réseau, l’une qui communique avec le réseau privé Beowulf pour les esclaves, l’autre pour le réseau à usage général de l’organisation.[13] Les ordinateurs esclaves ont généralement leur propre version du même système d'exploitation, ainsi que de la mémoire locale et de l'espace disque. Cependant, le réseau d'esclaves privé peut également disposer d'un serveur de fichiers volumineux et partagé qui stocke des données persistantes globales, auxquelles les esclaves ont accès, le cas échéant.[13]
Un cluster DEGIMA à 144 nœuds à usage spécifique est conçu pour exécuter des simulations astrophysiques à corps N utilisant le code de calcul parallèle Multiple-Walk, plutôt que des calculs scientifiques à usage général.[16]
En raison de la puissance de calcul croissante de chaque génération de consoles de jeu, une nouvelle utilisation a vu le jour: elles sont réutilisées dans des clusters de calcul haute performance (HPC). Certains exemples de clusters de consoles de jeu sont les clusters Sony PlayStation et Microsoft Xbox. Un autre exemple de produit de jeu grand public est le poste de travail Nvidia Tesla Personal Supercomputer, qui utilise plusieurs puces de processeur d’accélérateur graphique. Outre les consoles de jeu, vous pouvez également utiliser des cartes graphiques haut de gamme. L'utilisation de cartes graphiques (ou plutôt de leurs GPU) pour effectuer des calculs pour le calcul en grille est beaucoup plus économique que l'utilisation d'un processeur, même si elle est moins précise. Cependant, lorsque vous utilisez des valeurs à double précision, elles deviennent aussi précises que les processeurs et sont toujours beaucoup moins coûteuses (coût d'achat).[2]
Les clusters d’ordinateurs ont toujours fonctionné sur des ordinateurs physiques distincts dotés du même système d’exploitation. Avec l'avènement de la virtualisation, les nœuds de cluster peuvent s'exécuter sur des ordinateurs physiques distincts dotés de systèmes d'exploitation différents, décrits ci-dessus avec une couche virtuelle semblable.[17][[citation requise][[clarification nécessaire] Le cluster peut également être virtualisé sur diverses configurations au fur et à mesure de la maintenance. Un exemple d'implémentation est Xen en tant que gestionnaire de virtualisation avec Linux-HA.[17]
Partage de données et communication[[modifier]
Partage de données[[modifier]

Comme les grappes d’ordinateurs sont apparues dans les années 1980, il en a été de même pour les superordinateurs. L'un des éléments qui distinguaient les trois classes à cette époque était que les premiers superordinateurs utilisaient la mémoire partagée. À ce jour, les clusters n'utilisent généralement pas de mémoire physiquement partagée, mais de nombreuses architectures de superordinateurs l'ont également abandonnée.
Cependant, l'utilisation d'un système de fichiers en cluster est essentielle dans les clusters informatiques modernes.[[citation requise] Les exemples incluent le système de fichiers IBM General Parallel, les volumes partagés de cluster de Microsoft ou le système de fichiers de cluster Oracle.
Transmission de messages et communication[[modifier]
MPI (interface de transmission de messages) et PVM (machine virtuelle parallèle) sont deux approches largement utilisées pour la communication entre les nœuds de grappe.[18]
Le PVM a été développé au laboratoire national d'Oak Ridge vers 1989 avant que le MPI ne soit disponible. PVM doit être directement installé sur chaque nœud du cluster et fournit un ensemble de bibliothèques de logiciels décrivant le nœud en tant que "machine virtuelle parallèle". PVM fournit un environnement d'exécution pour la transmission de messages, la gestion des tâches et des ressources, et la notification des erreurs. PVM peut être utilisé par les programmes utilisateur écrits en C, C ++, Fortran, etc.[18][19]
MPI a émergé au début des années 90 à la suite de discussions entre 40 organisations. L'effort initial a été soutenu par l'ARPA et la National Science Foundation. Plutôt que de recommencer à zéro, la conception de MPI s’appuyait sur diverses fonctionnalités disponibles dans les systèmes commerciaux de l’époque. Les spécifications MPI ont ensuite donné lieu à des implémentations spécifiques. Les implémentations MPI utilisent généralement des connexions TCP / IP et socket.[18] MPI est maintenant un modèle de communication largement disponible qui permet d'écrire des programmes parallèles dans des langages tels que C, Fortran, Python, etc.[19] Ainsi, contrairement au PVM qui fournit une implémentation concrète, MPI est une spécification qui a été implémentée dans des systèmes tels que MPICH et Open MPI.[19][20]
Gestion de cluster[[modifier]

L'un des défis de l'utilisation d'un groupe d'ordinateurs est son coût d'administration, qui peut parfois être aussi élevé que celui de l'administration de N machines indépendantes, si le cluster compte N nœuds.[21] Dans certains cas, cela offre un avantage aux architectures de mémoire partagée avec des coûts d’administration moins élevés.[21] Cela a également rendu populaire les machines virtuelles, en raison de la facilité d'administration.[21]
Planification des tâches[[modifier]
Lorsqu'un grand groupe multi-utilisateurs doit accéder à de très grandes quantités de données, la planification des tâches devient un défi. Dans un cluster hétérogène CPU-GPU avec un environnement d'application complexe, les performances de chaque travail dépendent des caractéristiques du cluster sous-jacent. Par conséquent, le mappage des tâches sur les cœurs de processeur et les périphériques GPU constitue un défi majeur.[22] C'est un domaine de recherche en cours; Des algorithmes combinant et développant MapReduce et Hadoop ont été proposés et étudiés.[22]
Gestion des pannes de nœuds[[modifier]
Lorsqu'un nœud d'un cluster tombe en panne, des stratégies telles que la "séparation" peuvent être utilisées pour maintenir le reste du système opérationnel.[23][[meilleure source nécessaire][24] La clôture est le processus consistant à isoler un nœud ou à protéger des ressources partagées lorsqu'un nœud semble ne pas fonctionner correctement. Il existe deux classes de méthodes d’escrime; l'un désactive un nœud lui-même et l'autre interdit l'accès à des ressources telles que des disques partagés.[23]
La méthode STONITH signifie "Tirez sur l'autre nœud de la tête", ce qui signifie que le nœud suspect est désactivé ou mis hors tension. Par exemple, clôtures électriques utilise un contrôleur d'alimentation pour désactiver un nœud inutilisable.[23]
le ressources clôtures Cette approche interdit l’accès aux ressources sans mettre le nœud hors tension. Cela peut inclure clôture de réservation persistante via le SCSI3, une clôture Fibre Channel pour désactiver le port Fibre Channel ou une clôture GNBD (Global Network Block Device) pour désactiver l'accès au serveur GNBD.
Développement et administration de logiciels[[modifier]
Programmation parallèle[[modifier]
Les clusters d'équilibrage de charge, tels que les serveurs Web, utilisent des architectures de cluster pour prendre en charge un grand nombre d'utilisateurs. En règle générale, chaque demande d'utilisateur est acheminée vers un nœud spécifique, ce qui permet un parallélisme des tâches sans coopération multi-nœuds, car l'objectif principal du système est de fournir un service rapide à l'utilisateur. accès aux données partagées. Toutefois, les "clusters d’ordinateurs" qui effectuent des calculs complexes pour un petit nombre d’utilisateurs doivent tirer parti des capacités de traitement en parallèle du cluster et partitionner "le même calcul" entre plusieurs nœuds.[25]
La parallélisation automatique des programmes reste un défi technique, mais les modèles de programmation parallèle peuvent être utilisés pour obtenir un degré de parallélisme plus élevé via l'exécution simultanée de parties séparées d'un programme sur différents processeurs.[25][26]
Débogage et surveillance[[modifier]
Le développement et le débogage de programmes parallèles sur un cluster nécessitent des primitives de langage parallèle ainsi que des outils appropriés tels que ceux discutés par le. Forum de débogage haute performance (HPDF) qui a abouti aux spécifications HPD.[19][27]
Des outils tels que TotalView ont ensuite été développés pour déboguer des implémentations parallèles sur des clusters d’ordinateurs utilisant MPI ou PVM pour la transmission de messages.
Le système Berkeley NOW (réseau de stations de travail) recueille des données sur les grappes et les stocke dans une base de données, tandis qu'un système tel que PARMON, développé en Inde, permet l'observation visuelle et la gestion de grappes de grande taille.[19]
Le point de contrôle d'application peut être utilisé pour restaurer un état donné du système lorsqu'un nœud tombe en panne lors d'un calcul multi-nœud long.[28] Cela est essentiel dans les grandes grappes, étant donné que plus le nombre de nœuds est élevé, plus le risque de défaillance d'un nœud sous de lourdes charges de calcul augmente également. Le point de contrôle peut restaurer le système dans un état stable, ce qui permet au traitement de reprendre sans avoir à recalculer les résultats.[28]
Quelques implémentations[[modifier]
Le monde GNU / Linux prend en charge divers logiciels de cluster; pour le regroupement d'applications, il y a distcc et MPICH. Serveur virtuel Linux, Linux-HA – Clusters basés sur des administrateurs permettant de répartir les demandes de services entrantes sur plusieurs nœuds de cluster. MOSIX, LinuxPMI, Kerrighed, OpenSSI sont des grappes complètes intégrées au noyau qui permettent la migration automatique des processus entre noeuds homogènes. OpenSSI, openMosix et Kerrighed sont des implémentations d'images mono-système.
Le cluster d’ordinateurs Microsoft Windows Server 2003 basé sur la plate-forme Windows Server fournit des éléments pour le calcul hautes performances tels que le planificateur de travaux, la bibliothèque MSMPI et les outils de gestion.
gLite est un ensemble de technologies middleware créées par le projet Enabling Grids for E-science (EGEE).
slurm est également utilisé pour planifier et gérer certaines des plus grandes grappes de supercalculateurs (voir la liste des 500 principaux domaines).
Autres approches[[modifier]
Bien que la plupart des clusters d’ordinateurs soient des appareils permanents, des tentatives de calcul flash mob ont été tentées pour construire des clusters de courte durée pour des calculs spécifiques. Cependant, les systèmes informatiques volontaires à grande échelle tels que les systèmes basés sur BOINC ont eu plus de suiveurs.
Voir également[[modifier]
Références[[modifier]
- ^ "Cluster vs grid computing". Débordement de pile.
- ^ Bader, David; Pennington, Robert (mai 2001). "Cluster Computing: Applications". Georgia Tech College of Computing. Archivé de l'original le 2007-12-21. Récupéré 2017-02-28.
- ^ "Le supercalculateur d'armes nucléaires reconstitue le record mondial de vitesse pour les États-Unis". Le télégraphe. 18 juin 2012. Récupéré 18 juin 2012.
- ^ Gray, Jim; Rueter, Andreas (1993). Traitement des transactions: concepts et techniques. Morgan Kaufmann Publishers. ISBN 978-1558601901.
- ^ une b c Systèmes d'information en réseau: première conférence internationale, NBIS 2007. p. 375. ISBN 3-540-74572-6.
- ^ William W. Hargrove, Forrest M. Hoffman et Thomas Sterling (16 août 2001). "Le super-ordinateur à faire soi-même". Scientifique américain. 265 (2). pp. 72–79. Récupéré 18 octobre 2011.
- ^ Hargrove, William W .; Hoffman, Forrest M. (1999). "Cluster Computing: Linux poussé à l'extrême". Linux Magazine. Archivé de l'original le 18 octobre 2011. Récupéré 18 octobre 2011.
- ^ Yokokawa, Mitsuo; et al. (1-3 août 2011). The K computer: projet japonais de développement de superordinateurs de la prochaine génération. Symposium international sur l'électronique basse consommation et le design (ISLPED). pp. 371–372. doi: 10.1109 / ISLPED.2011.5993668.
- ^ Pfister, Gregory (1998). À la recherche de grappes (2e éd.). Upper Saddle River, NJ: Prentice Hall PTR. p. 36. ISBN 978-0-13-899709-0.
- ^ Hill, Mark Donald; Jouppi, Norman Paul; Sohi, Gurindar (1999). Lectures en architecture informatique. pp. 41–48. ISBN 978-1-55860-539-8.
- ^ une b Sloan, Joseph D. (2004). Clusters Linux hautes performances. ISBN 978-0-596-00570-2.
- ^ une b c ré Daydé, Michel; Dongarra, Jack (2005). Calcul haute performance pour la science informatique – VECPAR 2004. pp. 120-121. ISBN 978-3-540-25424-9.
- ^ "IBM Cluster System: Avantages". IBM. Archivé de l'original le 29 avril 2016. Récupéré 8 septembre 2014.
- ^ "Evaluation des avantages du clustering". Microsoft. 28 mars 2003. Archivé de l'original le 22 avril 2016. Récupéré 8 septembre 2014.
- ^ Hamada, Tsuyoshi; et al. (2009). "Nouvel algorithme parallèle multi-accès pour le code d'arborescence Barnes – Hut sur GPU – vers une simulation rentable et performante de N-corps". Informatique – Recherche et développement. 24 (1-2): 21–31. doi: 10.1007 / s00450-009-0089-1.
- ^ une b Mauer, Ryan (12 janvier 2006). "Xen Virtualization and Linux Clustering, Part 1". Journal Linux. Récupéré 2 juin 2017.
- ^ une b c Milicchio, Franco; Gehrke, Wolfgang Alexander (2007). Services distribués avec OpenAFS: pour l'entreprise et l'éducation. pp. 339–341. ISBN 9783540366348.
- ^ une b c ré e Prabhu, C.S.R. (2008). Calcul en grille et en cluster. pp. 109–112. ISBN 978-8120334281.
- ^ Gropp, William; Lusk, Ewing; Skjellum, Anthony (1996). "Une implémentation portable hautes performances de l'interface de transmission de messages MPI". Traitement en parallèle. 22 (6): 789–828. CiteSeerX 10.1.1.102.9485. doi: 10.1016 / 0167-8191 (96) 00024-5.
- ^ une b c Patterson, David A .; Hennessy, John L. (2011). Organisation et conception informatique. pp. 641–642. ISBN 978-0-12-374750-1.
- ^ une b K. Shirahata; et al. (30 nov. – 3 déc. 2010). Planification de tâches de carte hybride pour des clusters hétérogènes basés sur un processeur graphique. Technologie et science du cloud computing (CloudCom). pp. 733–740. doi: 10.1109 / CloudCom.2010.55. ISBN 978-1-4244-9405-7.
- ^ une b c Robertson, Alan (2010). "Clôture de ressources avec STONITH" (PDF). Centre de recherche IBM Linux.
- ^ Vargas, Enrique; Bianco, Joseph; Deeths, David (2001). Environnement Sun Cluster: Sun Cluster 2.2. Prentice Hall Professional. p. 58. ISBN 9780130418708.
- ^ une b Aho, Alfred V .; Blum, Edward K. (2011). Informatique: le matériel, les logiciels et le cœur de celui-ci. pp. 156–166. ISBN 978-1-4614-1167-3.
- ^ Rauber, Thomas; Rünger, Gudula (2010). Programmation parallèle: pour les systèmes multicœurs et en cluster. pp. 94–95. ISBN 978-3-642-04817-3.
- ^ Francioni, Joan M .; Pancake, Cherri M. (avril 2000). "Un standard de débogage pour l'informatique haute performance". Programmation scientifique. Amsterdam, Pays-Bas: IOS Press. 8 (2): 95-108. doi: 10.1155 / 2000/971291. ISSN 1058-9244.
- ^ une b Sloot, Peter, éd. (2003). Science computationnelle– ICCS 2003: Conférence internationale. pp. 291–292. ISBN 3-540-40195-4.
Lectures complémentaires[[modifier]
- Baker, Mark; et al. (11 janv. 2001). "Livre blanc sur le clustering". arXiv:cs / 0004014.
- Marcus, Evan; Stern, Hal (2000-02-14). Plans de haute disponibilité: conception de systèmes distribués résilients. John Wiley & Sons. ISBN 978-0-471-35601-1.
- Pfister, Greg (1998). À la recherche de grappes. Prentice Hall. ISBN 978-0-13-899709-0.
- Buyya, Rajkumar, éd. (1999). Cluster Computing Haute Performance: architectures et systèmes. 1. NJ, USA: Prentice Hall. ISBN 978-0-13-013784-5.
- Buyya, Rajkumar, éd. (1999). Cluster Computing Haute Performance: architectures et systèmes. 2. NJ, USA: Prentice Hall. ISBN 978-0-13-013785-2.
Liens externes[[modifier]






Commentaires
Laisser un commentaire