
Comment obtenir plus de vos données de journal – Serveur d’impression






Sommaire
Exploitation forestière: nous devrions faire cela mieux maintenant!
Qu'est ce que je veux dire? Il existe de nombreux frameworks et bibliothèques de journalisation Java, et la plupart des développeurs en utilisent un ou plusieurs tous les jours. Les exemples les plus courants pour les développeurs Java sont log4j et logback. Ils sont simples et faciles à utiliser et fonctionnent très bien pour les développeurs. Les fichiers journaux Java de base ne suffisent tout simplement pas, mais nous avons quelques bonnes pratiques et astuces Java pour vous aider à en tirer le meilleur parti!
Avez-vous déjà eu à travailler avec vos fichiers journaux une fois que votre application a quitté le développement? Si c'est le cas, vous rencontrez rapidement quelques problèmes.
- Il y a beaucoup plus de données.
- Vous devez avoir accès aux données.
- Ses répartis sur plusieurs serveurs.
- Une opération spécifique peut être répartie sur plusieurs applications. Vous avez donc encore plus de journaux à explorer.
- C’est plat et difficile à interroger; même si vous le mettez en SQL, vous allez devoir faire une indexation de texte intégral pour le rendre utilisable.
- C’est difficile à lire; les messages sont brouillés comme des spaghettis.
- En général, vous n’avez aucun contexte de l’utilisateur, etc.
- Il manque probablement des détails utiles. (Vous voulez dire "log.Info (" dans la méthode ")" n’est pas utile ???)
- Vous allez gérer la rotation et la conservation des fichiers journaux.
De plus, vous avez toutes ces données riches sur votre application qui sont générées et vous ne pouvez tout simplement pas mise au travail de manière proactive.
Il est temps de se préoccuper sérieusement de la journalisation
Une fois que vous travaillez sur une application qui ne s'exécute pas sur votre bureau, les messages de journalisation (y compris les exceptions) constituent généralement votre seule bouée de sauvetage. rapidement découvrir pourquoi quelque chose dans votre application ne fonctionne pas correctement. Sûr, Les outils APM peuvent vous alerter des fuites de mémoire et des goulots d’étranglement liés aux performances, mais manquent généralement de suffisamment de détails pour vous aider à résoudre un problème spécifique, c’est-à-dire pourquoi. cette utilisateur se connecter, ou pourquoi pas cette traitement des enregistrements?
Chez Stackify, nous avons créé une «culture de la journalisation» visant à atteindre ces objectifs:
- Connectez-vous toutes les choses. Connectez-vous autant que possible pour avoir toujours des journaux pertinents et contextuels qui n’ajoutent pas de temps système.
- Travaillez plus intelligemment, pas plus fort. Consolidez et agrégez toute notre journalisation dans un emplacement central, accessible à tous les développeurs, et facile à distiller. En outre, trouver de nouvelles façons pour nos données de journalisation et d’exception de nous aider de manière proactive améliorer notre produit.

Dans cet article, nous allons explorer ces meilleures pratiques et partager ce que nous avons fait pour y remédier, dont une grande partie fait maintenant partie du produit de gestion des journaux de Stackify. De plus, si vous n’avez pas utilisé Prefix pour afficher vos journaux, n’oubliez pas de le vérifier!
Début Enregistrer toutes les choses!
J'ai travaillé dans de nombreux magasins où les messages de journalisation ressemblaient à ceci:
Je donnerai du crédit au développeur; au moins ils utilisent un try / catch et manipulent l'exception. L’exception aura probablement une trace de pile, donc je sais à peu près d’où elle vient, mais pas d'autre contexte est connecté.
Parfois, ils font même une journalisation plus proactive, comme ceci:
Mais en règle générale, de telles déclarations n’aident pas beaucoup à vous informer de ce qui se passe réellement dans votre application. Si vous êtes chargé de dépanner une erreur de production et / ou qu'elle survient pour un seul (ou un sous-ensemble) des utilisateurs de l'application, cela ne vous laisse pas beaucoup à faire, en particulier lorsque vous examinez votre instruction de journal. pourrait être une aiguille dans une botte de foin dans une application très utilisée.
Comme je l’ai mentionné plus tôt, la journalisation est souvent l’une des rares lignes de vie que vous avez dans les environnements de production où vous ne pouvez pas physiquement connecter et déboguer. Vous souhaitez enregistrer autant de données contextuelles pertinentes que possible. Voici nos principes directeurs pour le faire.
Marcher le code
Supposons que vous souhaitiez ajouter une procédure de journalisation afin que vous puissiez voir ce qui s’est passé. Toi pourrait faites simplement un essai / accrochage et gérez les exceptions (ce que vous devriez) mais cela ne vous dit pas grand chose ce qui a été passé dans la demande. Jetez un coup d'œil à l'exemple suivant simplifié à l'extrême.
classe publique Foo privé int id; double valeur privée; public Foo (int id, double valeur) this.id = id; this.value = valeur; public int getId () id de retour; public double getValue () valeur de retour;
Prenez la méthode d'usine suivante, qui crée un Foo. Notez comme j'ai ouvert la porte à l'erreur – la méthode prend un double comme paramètre d'entrée. J'appelle doubleValue () mais je ne vérifie pas la valeur null. Cela pourrait provoquer une exception.
classe publique FooFactory public statique Foo createFoo (int id, Double valeur) retourne new Foo (id, value.doubleValue ());
C'est un scénario simple, mais il remplit bien son rôle. En supposant qu’il s’agisse d’un aspect très critique de mon application Java (aucun échec de Foos!), Ajoutons quelques informations de base pour nous permettre de savoir ce qui se passe.
classe publique FooFactory
Logger statique privé LOGGER = LoggerFactory.getLogger (FooFactory.class);
public statique Foo createFoo (int id, Double valeur)
LOGGER.debug ("Créer un Foo");
essayer
Foo foo = new Foo (id, value.doubleValue ());
LOGGER.debug ("", toto);
retourne foo;
catch (Exception e)
LOGGER.error (e.getMessage (), e);
return null;
Maintenant, créons deux foos; un qui est valide et l'autre qui ne l'est pas:
FooFactory.createFoo (1, Double.valueOf (33.0)); FooFactory.createFoo (2, null);
Et maintenant, nous pouvons voir une journalisation, et cela ressemble à ceci:
2017-02-15 17: 01: 04,842 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 01: 04,848 [main] DEBUG com.stackifytest.logging.FooFactory: com.stackifytest.logging.Foo@5d22bbb7 2017-02-15 17: 01: 04,849 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 01: 04,851 [main] Erreur com.stackifytest.logging.FooFactory: java.lang.NullPointerException sur com.stackifytest.logging.FooFactory.createFoo (FooFactory.java:15) à com.stackifytest.logging.FooFactoryTest.test (FooFactoryTest.java:11)
Nous avons maintenant une journalisation – nous savons quand les objets Foo sont créés et quand ils ne parviennent pas à être créés dans createFoo (). Mais il nous manque un contexte qui aiderait. L'implémentation par défaut de toString () ne génère pas de données sur les membres de l'objet. Nous avons quelques options ici, mais demandons à l’EDI de générer une implémentation pour nous.
@Passer outre chaîne publique toString () retour "Foo [id=" + id + ", value=" + value + "]";
Relancez notre test:
2017-02-15 17: 13: 06,032 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 13: 06,041 [main] DEBUG com.stackifytest.logging.FooFactory: Foo [id=1, value=33.0] 2017-02-15 17: 13: 06,041 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 13: 06,043 [main] Erreur com.stackifytest.logging.FooFactory: java.lang.NullPointerException sur com.stackifytest.logging.FooFactory.createFoo (FooFactory.java:15) à com.stackifytest.logging.FooFactoryTest.test (FooFactoryTest.java:11)
Beaucoup mieux! Maintenant, nous pouvons voir l'objet qui a été enregistré comme "[id=, value=]”. Une autre option que vous avez pour toString consiste à utiliser les capacités de réflexion de Javas. Le principal avantage ici est que vous n’avez pas à modifier la méthode toString lorsque vous ajoutez ou supprimez des membres. Voici un exemple utilisant la bibliothèque Gson de Google. Maintenant, regardons le résultat:
2017-02-15 17: 22: 55,584 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 22: 55,751 [main] DEBUG com.stackifytest.logging.FooFactory: "id": 1, "valeur": 33,0 2017-02-15 17: 22: 55,754 [main] DEBUG com.stackifytest.logging.FooFactory: Créer un foo 2017-02-15 17: 22: 55,760 [main] Erreur com.stackifytest.logging.FooFactory: java.lang.NullPointerException sur com.stackifytest.logging.FooFactory.createFoo (FooFactory.java:15) à com.stackifytest.logging.FooFactoryTest.test (FooFactoryTest.java:11)
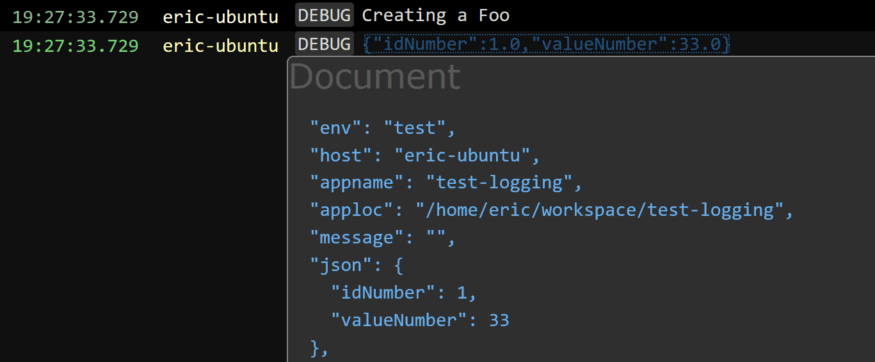
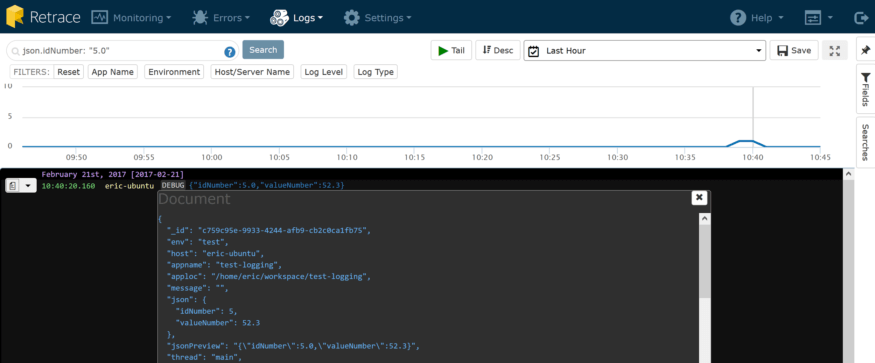
Lorsque vous enregistrez des objets au format JSON et que vous utilisez l’outil Retrace de Stackify, vous pouvez obtenir de jolis détails comme celui-ci:
Visualiseur JSON du tableau de bord de la consignation de retraçage
Journalisation Plus de détails avec les contextes de diagnostic
Et cela nous amène à un dernier point sur la journalisation plus en détail: la journalisation de contexte de diagnostic. Lorsqu’il s’agit de déboguer un problème de production, le message «Création d’un toto» peut figurer des milliers de fois dans vos journaux, sans que l’on sache qui est l’utilisateur connecté qui l’a créé. Savoir qui était l'utilisateur est le genre de contexte qui n'a pas de prix pour pouvoir résoudre rapidement un problème. Pensez aux autres détails qui pourraient être utiles – par exemple, les détails HttpWebRequest. Mais qui veut se rappeler de le connecter à chaque fois? Enregistrement du contexte de diagnostic à la rescousse, en particulier le contexte de diagnostic mappé. En savoir plus sur le MDC de SLF4J ici: https://logback.qos.ch/manual/mdc.html.
Le moyen le plus simple d’ajouter des éléments de contexte à votre journalisation est généralement un filtre de servlet. Pour cet exemple, créons un filtre de servlet qui génère un identifiant de transaction et le relie au MDC.
Classe publique LogContextFilter implémente Filter
public void init (configuration FilterConfig)
public void destroy ()
public void doFilter (demande ServletRequest, réponse ServletResponse, chaîne FilterChain) lève ServletException, IOException
String transactionId = UUID.randomUUID (). ToString ();
MDC.put ("TRANS_ID", transactionId);
essayer
chain.doFilter (demande, réponse);
enfin
MDC.clear ();
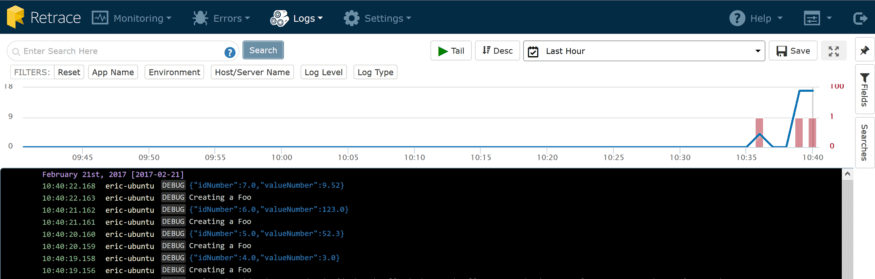
Maintenant, nous pouvons voir certaines instructions du journal comme ceci:
![]()
Plus de contexte. Nous pouvons maintenant suivre toutes les instructions de journal à partir d'une seule demande.
Cela nous amène au sujet suivant, qui est Travailler plus dur, pas plus intelligent. Mais avant cela, je vais répondre à une question que je suis sûr d’entendre beaucoup dans les commentaires: «Mais si je me connecte tout Cela ne créera-t-il pas de surcharge, de bavardages inutiles et d’énormes fichiers journaux? »Ma réponse se résume en deux parties: d’abord, utilisez les niveaux de verbosité de la journalisation. vous pouvez LOGGER.debug () tout ce dont vous pensez avoir besoin, puis configurez votre configuration pour la production de manière appropriée, c’est-à-dire uniquement Avertissement et supérieur. Lorsque vous avez besoin des informations de débogage, il ne s'agit que de modifier un fichier de configuration et non de redéployer du code. Deuxièmement, si vous vous connectez à un asynchrone, non bloquantalors les frais généraux devraient être faibles. Enfin, si vous êtes préoccupé par la rotation de l’espace et des fichiers journaux, il existe des moyens plus intelligents de le faire. Nous en reparlerons dans la section suivante.
Travailler plus intelligemment, pas plus dur
Maintenant que nous nous connectons tout, et comme il fournit des données plus contextuelles, nous allons examiner la partie suivante de l’équation. Comme je l’ai déjà dit et démontré, le simple fait de tout transférer dans des fichiers plats ne vous aide toujours pas beaucoup dans une application et un environnement vastes et complexes. Si vous prenez en compte des milliers de demandes, des fichiers s'étendant sur plusieurs jours, des semaines ou plus, et sur plusieurs serveurs, vous devez déterminer comment vous allez rapidement trouver les données dont vous avez besoin.
Ce dont nous avons tous besoin, c’est d’une solution offrant:
- Agrège toutes les données de journal et d'exception en un seul endroit
- Le rend disponible, instantanément, à tous les membres de votre équipe
- Présente une chronologie de journalisation sur l'ensemble de votre pile / infrastructure
- Est hautement indexé et consultable en étant dans un format structuré
C'est la partie où je vous parle de Stackify Retrace. Alors que nous cherchions à améliorer notre propre capacité à travailler rapidement et efficacement avec nos données de journal, nous avons décidé d’en faire un élément central de notre produit (oui, nous utilisons Stackify pour surveiller Stackify) et de le partager avec nos clients, car nous pensons que c’est un élément clé. question centrale pour le dépannage des applications.
Premièrement, nous réalisons que beaucoup de développeurs ont déjà une connexion en place et ne voudront pas prendre beaucoup de temps pour extraire ce code et y insérer un nouveau code. C'est pourquoi nous avons créé des appenders de journalisation pour les applications les plus courantes. Cadres de journalisation Java.
En continuant avec log4j comme exemple, la configuration est facile. Ajoutez simplement l’appendeur Stackify au fichier maven pom de votre projet.
com.stackify stackify-log-log4j12 1.1.9 runtime
Ajoutez également une certaine configuration pour Stackify Appender à votre fichier logging.properties.
log4j.rootLogger = DEBUG, CONSOLE, STACKIFY log4j.appender.CONSOLE = org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.layout = org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern =% d [%t] % -5p% c:% m% n log4j.appender.STACKIFY = com.stackify.log.log4j12.StackifyLogAppender log4j.appender.STACKIFY.apiKey =[HIDDEN] log4j.appender.STACKIFY.application = journalisation-test log4j.appender.STACKIFY.environment = test
Comme vous pouvez le constater, si vous utilisez déjà un appender différent, vous pouvez le garder en place et le placer côte à côte. Maintenant que vos journaux sont en streaming sur Stackify, nous pouvons examiner le tableau de bord de journalisation. (À propos, si notre agent de surveillance est installé, vous pouvez également envoyer des entrées Syslog à Stackify!)
Ce tableau de bord présente un flux consolidé de données de journal provenant de tous vos serveurs et applications, présenté dans une chronologie. De là, vous pouvez rapidement
- Afficher les journaux en fonction d'une plage de temps
- Filtrer pour des serveurs, des applications ou des environnements spécifiques
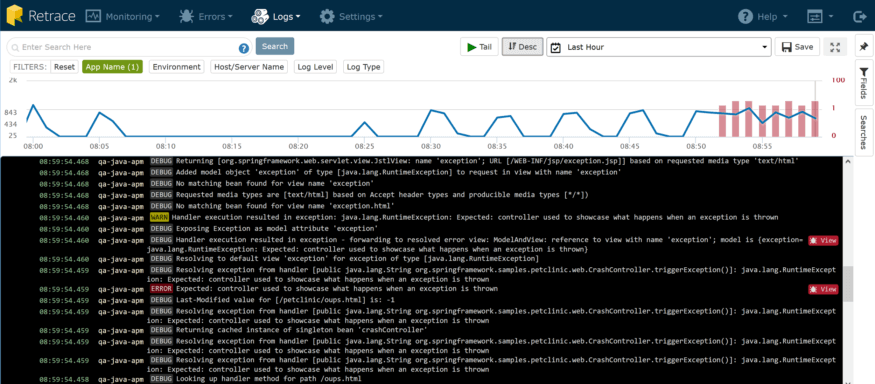
De plus, quelques fonctionnalités très utiles d’utilisation sont intégrées. Une des premières choses que vous remarquerez est le graphique situé en haut. C’est un excellent moyen de «trier» rapidement votre demande. La ligne bleue indique le taux de messages du journal et les barres rouges, le nombre d'exceptions enregistrées.
Il est clair qu’il ya quelques minutes, mon application Web a commencé à avoir une activité beaucoup plus cohérente, mais plus important encore, nous avons commencé à avoir plus d’exceptions à peu près au même moment. Les exceptions ne sont pas génératrices de frais généraux pour votre processeur et votre mémoire, elles peuvent également avoir un impact direct sur la satisfaction de l'utilisateur, ce qui peut coûter de l'argent.
En effectuant un zoom avant sur le graphique pour cette période, je peux rapidement filtrer les détails de mon journal jusqu'à cette période et consulter les journaux pour cette période.
Rechercher vos journaux
Voyez-vous ce texte bleu ci-dessous qui ressemble à un objet JSON?
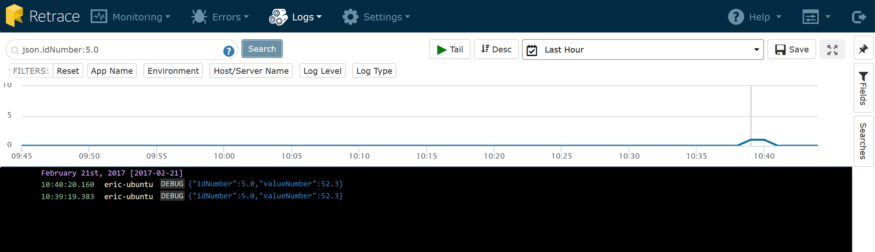
Bien est un objet JSON. C’est le résultat de la journalisation des objets et de l’ajout antérieur des propriétés de contexte. Cela a l'air beaucoup plus beau qu'un texte brut dans un fichier plat, n'est-ce pas? Eh bien, ça devient encore plus génial. Voir le champ de recherche en haut de la page? Je peux mettre dans n'importe quelle chaîne de recherche que je peux penser, et ce sera interroger tous mes journaux comme s'il s'agissait d'un fichier plat. Comme nous en avons déjà discuté, ce n’est pas génial parce que vous pourriez vous retrouver avec beaucoup plus de matchs que vous le souhaitez. Supposons que je souhaite rechercher tous les objets ayant un identifiant de 5. Heureusement, notre agrégateur de journaux est assez intelligent pour vous aider dans cette situation. C’est parce que lorsque nous trouvons des objets sérialisés dans les journaux, nous indexons chaque champ trouvé. Cela facilite la recherche comme ceci:
json.idNumber: 5.0
Cette recherche donne les résultats suivants:
Vous voulez savoir quoi d'autre vous pouvez rechercher? Cliquez simplement sur l'icône du document lorsque vous survolez un enregistrement de journal pour afficher tous les champs indexés par Stackify. La possibilité de tirer davantage parti de vos journaux et d'effectuer des recherches dans tous les champs s'appelle un enregistrement structuré.
Exploration de Java Détails d'exception
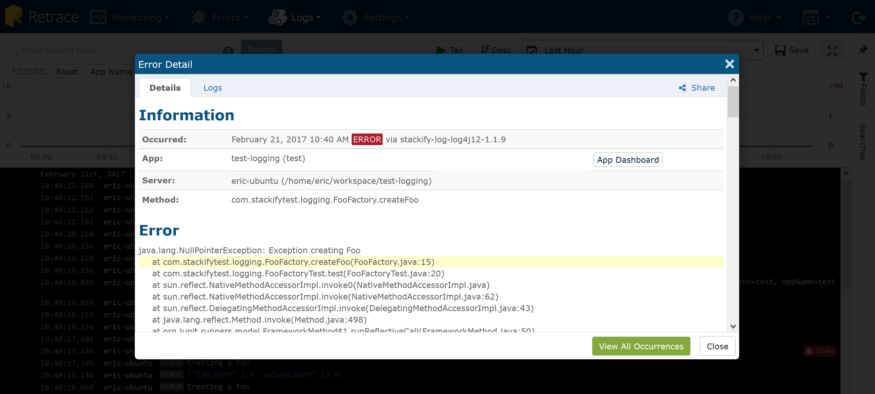
Vous avez peut-être aussi remarqué cette petite icône de bogue rouge () à côté des messages d'exception. C’est parce que nous traitons les exceptions différemment en affichant automatiquement plus de contexte. Cliquez dessus et nous présentons une vue plus profonde de cette exception.
Nos bibliothèques récupèrent non seulement la trace complète de la pile, mais également tous les détails de la requête Web, y compris les en-têtes, les chaînes de requête et les variables de serveur, le cas échéant. Dans ce mode, il existe un onglet «Journaux» qui vous donne une vue pré-filtrée de la journalisation à partir de l'application qui a généré l'erreur, sur le serveur où elle s'est produite, pendant une fenêtre temporelle étroite avant et après l'exception, pour donner plus de contexte autour de l'exception. Vous voulez savoir à quel point cette erreur est fréquente ou fréquente ou si vous souhaitez voir des détails sur d'autres occurrences? Cliquez sur le bouton «Afficher toutes les occurrences» et le tour est joué!
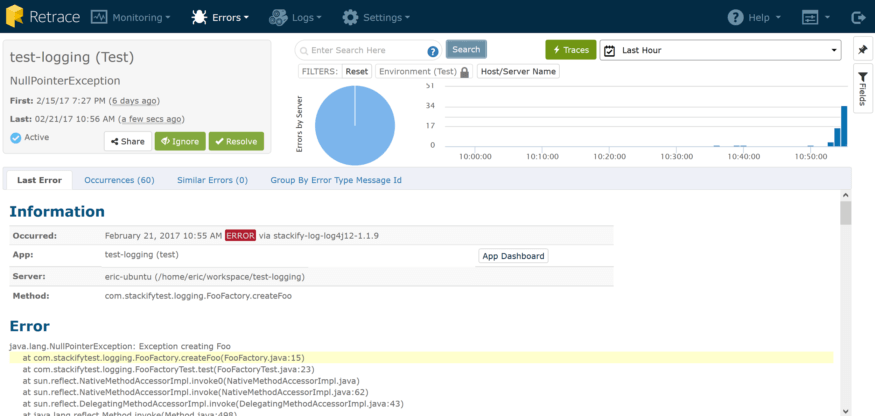
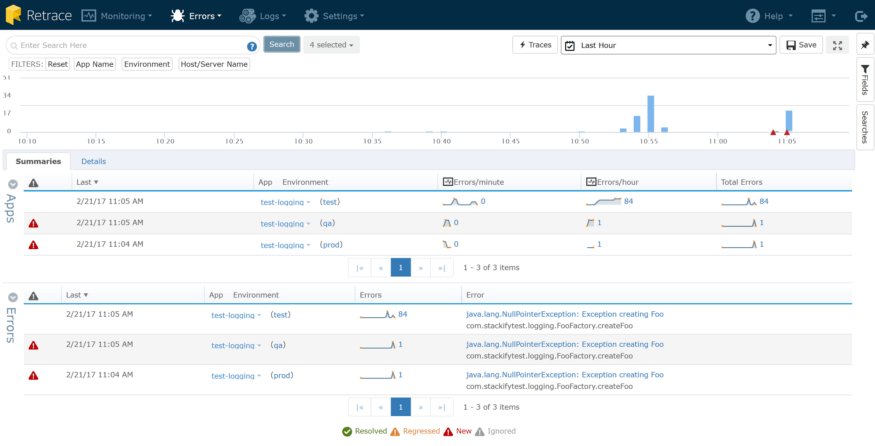
Je peux rapidement voir que cette erreur s’est produite 60 fois au cours de la dernière heure. Les erreurs et les journaux sont étroitement liés, et dans une application où une énorme quantité de journalisation peut avoir lieu, des exceptions peuvent parfois être un peu perdues dans le bruit. C’est pourquoi nous avons construit un Errors Dashboard également, pour vous donner cette même vue consolidée mais limitée aux exceptions.
Ici, je peux voir quelques excellentes données:
- J'ai eu une légère hausse de mon taux d'exceptions au cours des dernières minutes.
- La majorité de mes erreurs proviennent de mon environnement de test, soit environ 84 par heure.
- J'ai quelques nouvelles erreurs qui commencent à se produire (comme indiqué par les triangles rouges).
Avez-vous déjà mis en production une nouvelle version de votre application et vous vous demandez ce que l’assurance-qualité a manqué? (Ce n’est pas que je disais à QA de rater un bogue…) Erreur Tableau de bord à la rescousse. Vous pouvez regarder en temps réel et voir une tendance – beaucoup de triangles rouges, beaucoup de nouveaux bugs. Grand pic dans le graphique? Vous avez peut-être une utilisation accrue, de sorte qu'une erreur précédemment connue est davantage touchée; peut-être un code erroné (comme un pool de connexions SQL qui fuit) s'est-il éteint et provoque un taux d'erreurs de délai d'attente SQL plus élevé que la normale.
Il n’est pas difficile d’imaginer un grand nombre de scénarios différents pour lesquels cela pourrait fournir une alerte et une détection rapides. Hmm. Alerte précoce et détection. Cela soulève un autre grand sujet.
Moniteur
Ne serait-il pas agréable d’être alerté lorsque
- Un taux d'erreur pour une application ou un environnement spécifique augmente soudainement?
- Une erreur spécifiquement résolue commence à se reproduire?
- Une certaine action que vous enregistrez ne se produit pas assez souvent, etc.?
Stackify peut faire tout cela. Jetons un coup d’œil à chacun.
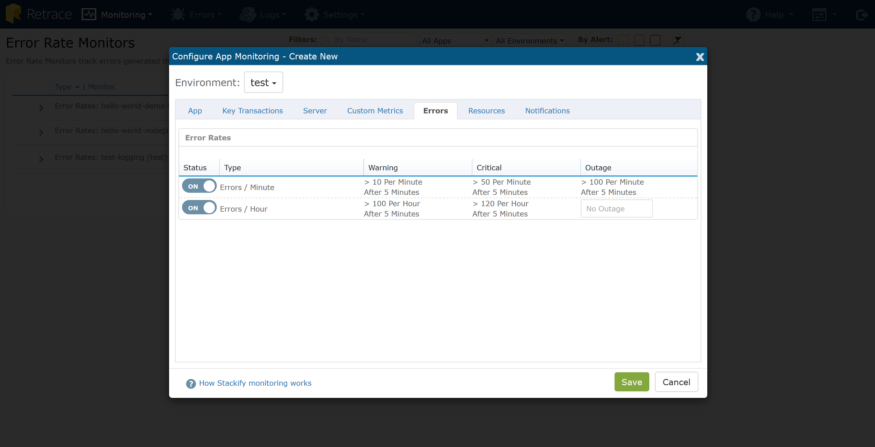
Taux d'erreur
Lorsque nous avons examiné le tableau de bord des erreurs, j’ai constaté que mon environnement de test recevait un nombre élevé d’erreurs par heure. Dans le tableau de bord des erreurs, cliquez sur «Taux d'erreur», puis sélectionnez l'application / l'environnement pour lequel vous souhaitez configurer des alertes:
Je peux configurer les moniteurs pour «Erreurs / minute» et «Total des erreurs 60 dernières minutes», puis choisir l'onglet «Notifications» pour spécifier qui doit être alerté et comment. Par la suite, si vous utilisez Stackify Monitoring, je peux également configurer ici toutes mes autres alertes: état de fonctionnement de l'application, utilisation de la mémoire, compteurs de performance, métriques personnalisées, contrôles de ping, etc.
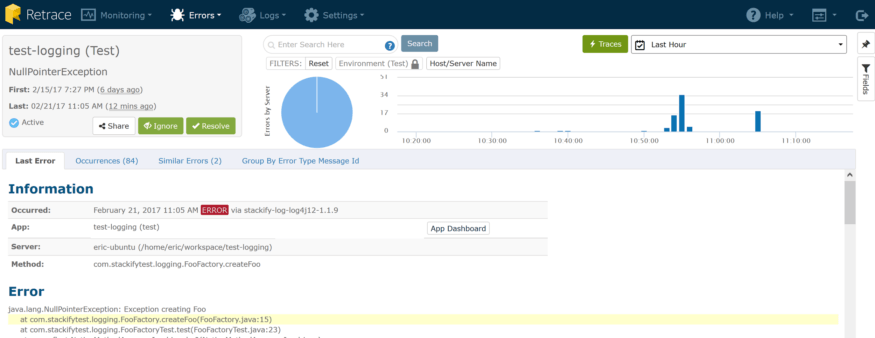
Erreurs résolues et nouvelles erreurs
Plus tôt, j'avais introduit une nouvelle erreur en ne vérifiant pas les valeurs nulles lors de la création d'objets Foo. Depuis, j’ai corrigé le problème et confirmé en vérifiant les détails de cette erreur particulière. Comme vous pouvez le constater, la dernière fois que cela s'est produit était il y a 12 minutes:
C'était une erreur stupide, mais facile à commettre. Je vais marquer celui-ci comme «résolu», ce qui me permet de faire quelque chose de vraiment cool: recevoir une alerte si elle revient. Le menu Notifications me permet de vérifier ma configuration et, par défaut, je suis configuré pour recevoir des notifications d’erreur nouvelles et régressées pour toutes mes applications et tous mes environnements.
Maintenant, si la même erreur se reproduit à l'avenir, je vais recevoir un courrier électronique sur la régression, qui apparaîtra dans le tableau de bord en tant que tel. Il s’agit là d’un petit peu d’automatisation pour vous aider lorsque vous «pensez» que vous avez résolu le problème et que vous voulez vous en assurer.
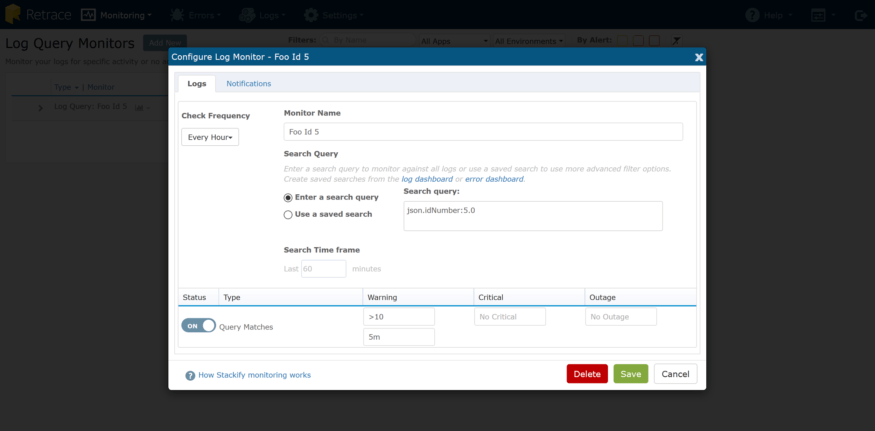
Journal Moniteurs
Certaines choses ne sont pas très simples à surveiller. Vous avez peut-être un processus critique qui s'exécute de manière asynchrone et le seul enregistrement de son succès (ou de son échec) est la consignation des instructions. Plus tôt dans ce billet, j’ai montré la capacité de lancer des requêtes approfondies contre votre données de journal structurées, et n'importe laquelle de ces requêtes peuvent être enregistrées et surveillées. J'ai un scénario très simple ici: ma requête est exécutée toutes les minutes et nous pouvons contrôler le nombre d'enregistrements correspondants que nous avons.
C’est un moyen simple et efficace de vérifier la santé du système si un fichier journal est votre seule indication.
Meilleures pratiques de journalisation Java
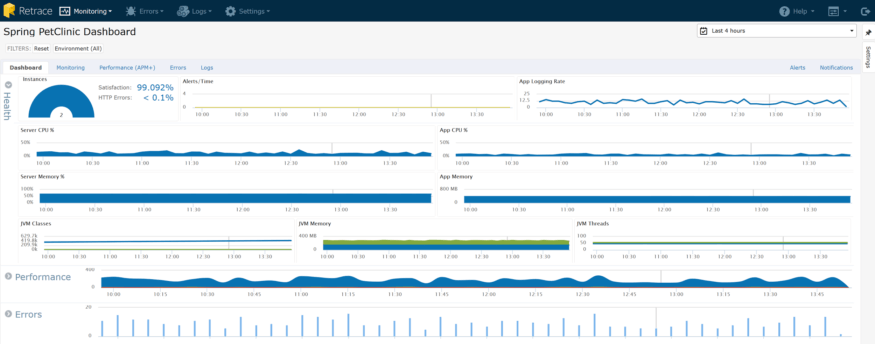
Toutes ces erreurs et les données de journal peuvent être inestimables, en particulier lorsque vous prenez du recul et que vous regardez une image légèrement plus grande. Vous trouverez ci-dessous le tableau de bord des applications d'une application Web Java contenant toutes les fonctions de surveillance:
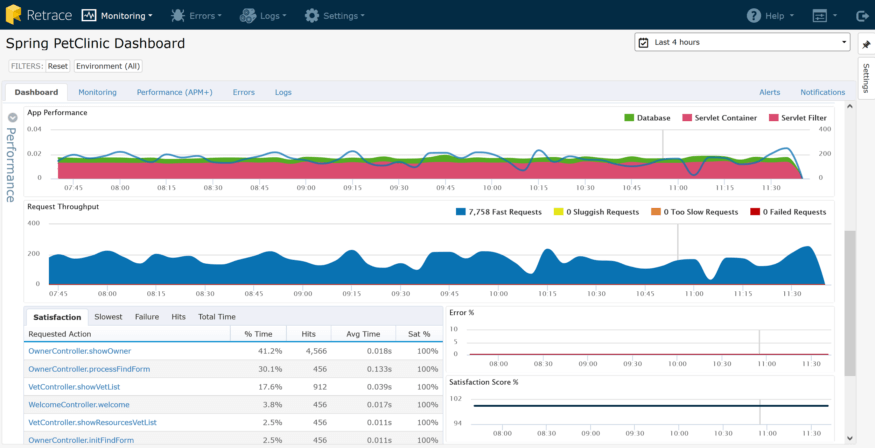
Comme vous pouvez le constater, vous obtenez rapidement d’excellentes données contextuelles auxquelles les erreurs et les journaux contribuent: Taux de satisfaction et d’erreur HTTP. Vous pouvez constater que le taux de satisfaction des utilisateurs est élevé et que le taux d’erreur HTTP est faible. Vous pouvez rapidement commencer à explorer pour voir quelles pages risquent de ne pas bien fonctionner et quelles erreurs se produisent:
Il y avait beaucoup de choses à couvrir dans ce billet, et j'ai l'impression d'avoir à peine rayé la surface. Si vous creusez un peu plus ou même si vous mettez la main dessus, vous le pouvez! J'espère que ces meilleures pratiques de journalisation Java vous aideront à rédiger de meilleurs journaux et à gagner du temps en dépannage.
Tous nos ajouts de journalisation Java sont disponibles sur GitHub et vous pouvez vous inscrire pour un essai gratuit pour commencer à utiliser Stackify dès aujourd'hui!
À propos de Stackify
Stackify offre aux équipes de développeurs une visibilité et un aperçu inégalés de la santé et du comportement des applications, à la fois de manière proactive dans un rôle de surveillance et de manière réactive dans un rôle de dépannage, tout en éliminant le besoin de se connecter à des serveurs et à d'autres ressources afin d'étudier les problèmes des applications.






Commentaires
Laisser un commentaire