
Deep TabNine: Comment fonctionne un autocompléteur de code AI? – Serveur d’impression

Un système d'exploitation smartphone moyen contient plus de 10 millions de lignes de code. Il faut 18 000 pages pour imprimer un million de lignes de code, ce qui correspond à 14 fois la guerre et la paix de Tolstoï.
Bien que le nombre de lignes de code ne soit pas une mesure directe de la qualité d'un développeur, il indique la quantité générée au fil des ans.

Il existe toujours une version plus simple et plus courte du code, ainsi qu'une version plus longue et exhaustive. Que se passe-t-il s'il existe un outil qui utilise des algorithmes d'apprentissage automatique pour sélectionner le code le plus approprié et afficher un menu déroulant? Il y en a un maintenant – Deep TabNine.
le développeurs derrière TabNine ont introduit Deep TabNine, qui est créé sous la forme d’un autocompléteur indépendant de la langue.

L'idée centrale ici est d'indexer le code et de détecter des schémas statistiques afin de faire de meilleures suggestions lors de l'écriture de code.
Cela apporte des gains supplémentaires en réactivité, fiabilité et facilité de configuration car TabNine n’a pas besoin de compiler le code.

Sommaire
GPT-2 Powered TabNine
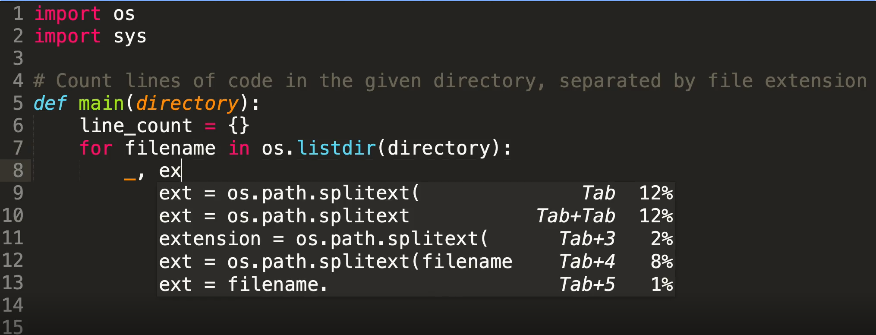
L’image ci-dessus montre comment, en tapant «ex», l’IDE demande aux options associées.
TabNine est un autocompléteur qui aide les développeurs à écrire du code plus rapidement. Pour améliorer la qualité des suggestions, l'équipe à l'origine de TabNine a ajouté un modèle d'apprentissage approfondi.
Deep TabNine est basé sur GPT-2, qui utilise le Transformateur Architecture de réseau. GPT-2 est un grand transformateurmodèle linguistique basé sur 1,5 milliard de paramètres, formé sur un ensemble de données de 8 millions de pages Web. GPT-2 est formé avec un objectif simple: prédire le mot suivant, étant donné tous les mots précédents dans un texte.
GPT-2 génère des échantillons de texte synthétiques en réponse à une entrée arbitraire du modèle. Il s'adapte au style et au contenu du texte de conditionnement. Cela permet à l'utilisateur de générer des continuations réalistes et cohérentes sur un sujet de son choix.
L’achèvement sémantique est fourni par un logiciel externe avec lequel TabNine communique à l’aide du Protocole de serveur de langue. TabNine est livré avec des scripts d’installation par défaut pour plusieurs serveurs de langue courants, entièrement configurables. Vous pouvez donc utiliser un autre serveur de langue ou ajouter un complément sémantique à une nouvelle langue.
Deep TabNine utilise des indices subtils auxquels les outils traditionnels ont difficilement accès. Par exemple, le type de retour de app.get_user () est supposé être un objet avec des méthodes de définition, tandis que le type de retour de app.get_users () est supposé être une liste.
Complétion automatique avec apprentissage en profondeur https://t.co/WenacHVj7z très cool! J’ai essayé des idées apparentées il y a très longtemps à l’époque des faits, mais ce n’était pas très utile à l’époque. Avec de nouveaux jouets (GPT-2) et plus de concentration, cela peut commencer à bien fonctionner. pic.twitter.com/XSV9O7yxpf
– Andrej Karpathy (@karpathy) 18 juillet 2019
Bien que la modélisation du code et la modélisation du langage naturel puissent sembler être des tâches non liées, la modélisation du code nécessite une compréhension inattendue de l'anglais.
Au lieu de se soucier de manquer une syntaxe triviale ou de définir une classe pour une fonctionnalité spécifique à une tâche, les développeurs peuvent désormais poursuivre leur travail à un niveau supérieur avec Deep TabNine optimisé par GPT-2 d’OpenAI.
Deep TabNine nécessite beaucoup de puissance de calcul et l’exécution du modèle sur un ordinateur portable aurait un temps de latence. Pour relever ce défi, l’équipe propose désormais un service qui permettra aux développeurs d’utiliser les serveurs de TabNine pour l’auto-complétion accélérée par le GPU. C'est appelé TabNine Cloud.
Pourquoi devrait-on opter pour TabNine?
- TabNine fonctionne pour tous les langages de programmation.
- TabNine ne nécessite aucune configuration pour fonctionner.
- TabNine ne nécessite aucun logiciel externe (bien qu'il puisse intégrer avec).
- Etant donné que TabNine n'analyse pas le code, il ne cessera jamais de fonctionner en raison d'un crochet mal assorti.
- Si le serveur de langue est lent, TabNine fournira ses propres résultats lors de l'interrogation du serveur de langue en arrière-plan. TabNine renvoie généralement ses résultats en 20 millisecondes.
Langues supportées:
Deep TabNine prend en charge Python, JavaScript, Java, C ++, C, PHP, Go, C #, Ruby, Objective-C, Rust, Swift, TypeScript, Haskell, OCaml, Scala, Kotlin, Perl, SQL, HTML, CSS et Bash.
Mettez la main sur Deep TabNine ici.

Histoires connexes
Fournissez vos commentaires ci-dessous






Commentaires
Laisser un commentaire