Un coup d'œil sur Intel's Ice Lake et Sunny Cove – Serveur d’impression
![]() Intel a lancé Ice Lake / Sunny Cove la semaine dernière et a révélé d'un seul coup tout ce que disait SemiAccurate au cours des dernières années. Mais ils n’ont pas cessé de creuser là-bas, continuant à éclipser tout ce qui était bien à propos de ce noyau tout en exaltant leurs difficultés à 10nm.
Intel a lancé Ice Lake / Sunny Cove la semaine dernière et a révélé d'un seul coup tout ce que disait SemiAccurate au cours des dernières années. Mais ils n’ont pas cessé de creuser là-bas, continuant à éclipser tout ce qui était bien à propos de ce noyau tout en exaltant leurs difficultés à 10nm.
Je vous ai répété:
Commençons par quelques mots sur le lac de glace et le 10 nm. Rappelez-vous il y a un peu plus de deux ans quand nous avons dit que 10nm était cassé et ne serait jamais plus rapide que le nœud 14nm actuel. Et nous vous avons montré où Intel avait déclaré cela directement dans les diapositives officielles? Les gens ne le croyaient pas alors et effacent encore la diapositive ci-dessous.
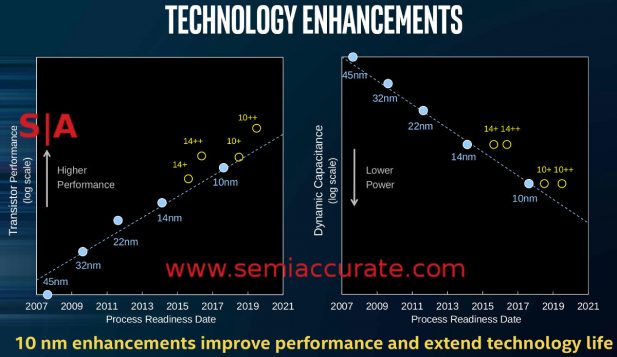
Glisser Bohring ce n'est pas
Jetez un coup d’œil à celui-ci dans le brief technique de Sunny Cove. Portez une attention particulière à la zone en haut à gauche qui indique le nombre maximum d’horloges centrales, et non la version productisée, c’était à un briefing sur le noyau lui-même. Pour une raison quelconque, Intel a catégoriquement refusé de donner des informations sur les UGS qu’ils ont lancées, presque comme s’ils étaient gênés.
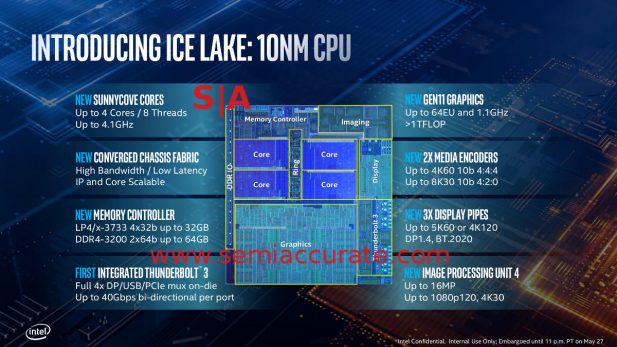
Seulement 1 GHz en bas
L’horloge de pointe théorique à 4,1 GHz est un nombre assez élevé, presque aussi élevé que celui d’AMD. Eh bien non, pas aussi élevé, mais élevé comparé aux noyaux de la dernière décennie. Malheureusement pour Intel, les produits n’ont pas atteint ce chiffre théorique pour une raison quelconque, ils n’atteignent que 3,9 GHz. Voici quelques exemples de références que Intel a refusé de distribuer.
 Le meilleur du lot 10nm
Le meilleur du lot 10nm
Encore 3.9 est un assez grand nombre pour les pièces mobiles, non? Oui, à moins que vous ne regardiez les offres actuelles d'Intel, qui atteignent à peine 4,9 GHz. Dans le même TDP. Oups. La photo ci-dessous a été divulguée en Chine et SemiAccurate a vérifié la plupart des chiffres et des noms. Nous avons placé un point bleu sur le SKU Ice Lake, au singulier, et un point rouge sur l’équivalent, beaucoup plus rapide, à 14 nm.
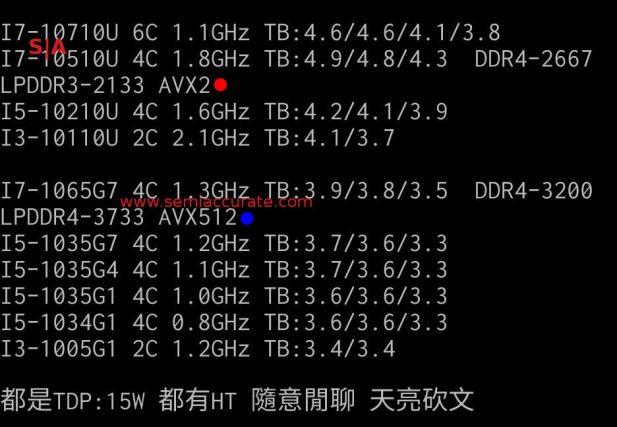
Différences douloureuses
Un plein GHz plus lent, pouvez-vous dire la mort sur les tablettes des magasins? Vous voyez maintenant pourquoi Intel a refusé de parler de produit et voulait uniquement parler de technologie des cœurs? Souhaitez-vous acheter une pièce TDP 4.9GHz 14nm 15W ou une pièce TDP 3.9GHz 10nm 15W pour votre prochain ordinateur portable? J'attendrai que vous cessiez de rire pour dire que les choses sont beaucoup plus proches qu'il n'y paraît à cause du nouveau noyau. Ensuite, ils enlèvent tout gain avec des cascades comme celle-ci en petits caractères.

Tout le reste avait des détails
La chose la plus positive que nous puissions tirer de quiconque chez Intel était:Nous pouvons atteindre la parité“. 10nm est cassé et n'aurait jamais dû être libéré. Il s’agit d’un oeil au beurre noir de plusieurs milliards de dollars pour la société. C’est pourquoi nous la publions plutôt que de la dissimuler sous le tapis. En faisant obstruction sur les SKU, Intel a cédé tout contrôle de la messagerie sur 10 nm et ne peut tout simplement pas atténuer l’impact de cette débâcle. La «parité» ne suffit pas après cinq ans de retard, pas d'excuses.
Intel ne peut pas fabriquer Ice Lake / Sunny Cove dans quelque volume que ce soit et ne sera probablement pas le meilleur des cas avant le début de 2020. L'année dernière, ils ont essayé une cascade encore plus embarrassante lors du lancement, et les résultats ont été pathétiques. Cette fois, il y a un volume réel, toutes les parties des processeurs peuvent parfois fonctionner, mais 10 nm ne cèdent toujours pas à un niveau proche de la viabilité économique. Les cœurs sont plutôt bons, et si Intel n’était pas aussi déterminé à détruire sa propre image, il aurait pu transformer cela en quelque chose d’intéressant.
Le Tech:
Qu'est-ce qui est si intéressant à propos de Sunny Cove? Commençons par le big bang, une augmentation de 18% de l'IPC, soit environ le double de celle de la dernière génération de cœurs libérés. Intel a commodément oublié Cannon Lake pour ces diapositives. Il s’agit donc de deux avancées générationnelles. Par conséquent, 18% correspond à peu près au même niveau qu’auparavant. Néanmoins, c’est une bonne chose au sens absolu, beaucoup plus rapide et plus efficace même si les régressions d’horloge sont supérieures à 18%. Net net, bonne conception de base entravée par un processus interrompu.
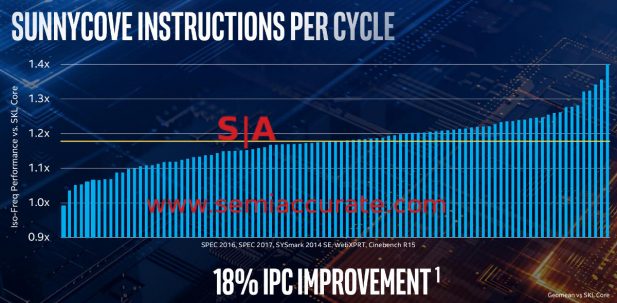
Pas mal mais moins que des régressions d'horloge
Comment Intel est-il arrivé ici? En allant large, beaucoup plus large qu'avant. L'allocation est augmentée de un à cinq, les ports d'exécution de deux à dix, plus de bande passante de magasin L1, un autre AGU pour un total de quatre, plus une autre unité de magasin pour un total de deux. En bref, cela s’élargit beaucoup plus et il en résulte un sérieux gain de CIP pour Ice Lake / Sunny Cove. Ça ressemble à ça.

Vague mais toujours manquant
Les caches ont également été améliorés, le prédicteur de branche a été renforcé et la latence de charge a également été réduite. Il y a beaucoup plus d'instructions vectorielles, y compris le quatuor VNNI de Cascade Lake et quelques autres bricoles. Ce qui est vraiment intéressant, c’est le nouveau jeu d’instructions d’IA révolutionnaire appelé BFloat16 qui fera ses débuts à Cooper Lake l’année prochaine. C’est intéressant parce que cette prochaine grande étape dans les accélérations de l’IA n’est pas dans le client ou le serveur d’Ice Lake, elle n’a pas été supprimée avant que la conception ne soit figée. Oops. Du côté positif, Ice dispose de deux unités AVX-512, l’une large de 512b et l’autre de seulement 256b, mais c’est un grand pas en avant.
Mise à jour du 5 juin 2019 à 16h05: Il existe deux unités AVX-512 d’une largeur de 256 bits chacune. Cela signifie que les utilisateurs centraux d'Ice Lake peuvent effectuer 2x opérations de 256 bb par cycle ou de 1 512 opérations, ce qui est beaucoup plus logique qu'un système asymétrique.
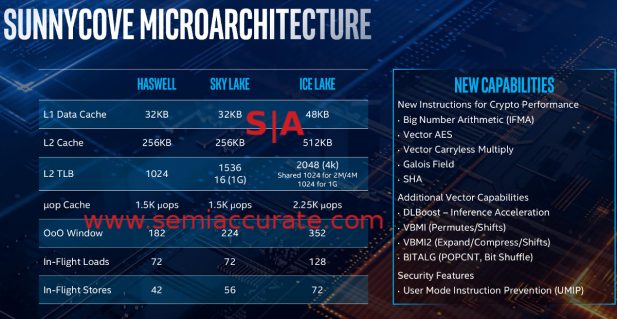
Enfin les bonnes choses
Une grande partie de ces augmentations de performances sont faciles à expliquer, une mémoire L1D 50% plus grande et un cache L2 doublé font des merveilles pour les taux de réussite. Le TLB obtient une augmentation en bonne santé, la mémoire cache uop enregistre une hausse et, en vol, les charges et les magasins augmentent également. Cela dit, si nous devions mettre le doigt sur le plus fort coup ici, nous indiquerions que la fenêtre OoO passe de 224 à 352 entrées, une augmentation plus que linéaire par rapport aux générations précédentes. Si vous additionnez toutes ces choses, vous obtenez un noyau beaucoup plus rapide et beaucoup plus efficace.
Si Intel pouvait produire un rendement sur Ice Lake et le synchroniser, cela aurait été une partie vraiment incroyable. Malheureusement, si vous n’avez pas compris le problème plus tôt, les rendements ne sont toujours pas viables et ils n’atteignent pas moins de 1 GHz plus lentement que leurs homologues à 14 nm. Sur les performances à filetage unique, la métrique la plus difficile à améliorer, Ice est un peu mieux que la Sky Part IV mais ne suffit pas à le remarquer. Notez que le tableau ci-dessous correspond au format ISO TDP. Le gain net est donc d’environ 5%.
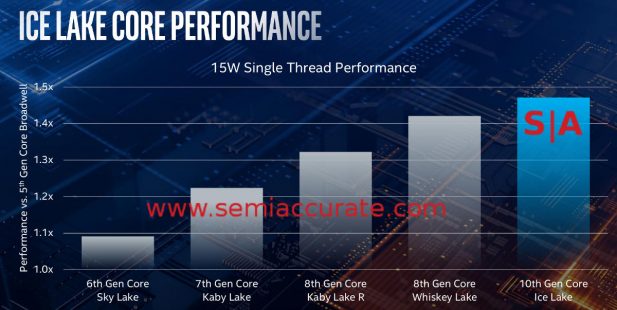
Performance à un seul fil
Uncore c'est mieux aussi:
Pour en arriver à la puce elle-même, de nombreux ajouts y figurent également. Le nouveau contrôleur de mémoire est le meilleur avec l'ajout de LPDDR4 / 4x à des vitesses allant jusqu'à 3733 MHz. Le côté graphique a également connu une forte augmentation avec le GPU Gen 11, un 1.12TF revendiqué des 64 EU tournant à 1,1 GHz. Ce GPU a été entièrement refait à partir des dernières pièces de la génération 9 pour une augmentation alléguée de 1,8 fois de la cadence. Vous ne savez pas pourquoi Intel compte 1, 2, 3, 4, 5, 6, 7, 8, 9, 11 bien que, * TOUJOURS *, mais il doit y avoir une raison quelque part.
Sur le côté vidéo, il existe maintenant deux encodeurs HEVC à fonction fixe pouvant traiter jusqu'à 4k60 4: 4: 4 ou 8K30 4: 2: 0. Du côté de la sortie, il y a trois sorties pouvant faire 3x 4K flux, 2x 5K ou un seul flux de 8K. Au moment de l'achat d'un panneau 8K, le silicium devrait être là pour le supporter, à condition qu'il ne soit pas artificiellement endommagé sur les SKU de bas de gamme. De toute façon, les sorties prennent en charge les signaux DP1.4 HBR et HDMI 2.0b, de sorte que toutes les bases sont assez bien couvertes.
La modification du GPU ne s'est pas limitée au niveau européen, la structure de la mémoire cache a également été considérablement réorganisée. Les graphiques de la génération 11 disposent désormais de 3 Mo de mémoire cache N3 dédiée et partagent 0,5 Mo avec les cœurs. De plus, les codeurs prendront en charge les largeurs matérielles 10b, ce qui constitue un pas en avant considérable avec une augmentation conséquente de la surface de silicium. Cela dit, si tout fonctionne comme prévu, les GPU Gen 11 devraient être assez complets. En passant, Intel semble avoir corrigé son pilote Linux au cours de la dernière année et ne figure donc plus sur notre liste de recommandations.
Il existe également une unité de traitement d’image et un îlot de capteur de faible puissance / DSP sur la matrice Ice. L’UPI peut traiter des images fixes jusqu’à 16 MP ou des vidéos 4K30, en gros, vous vous en tenez à votre téléphone portable. L'îlot DSP est destiné aux assistants vocaux, entre autres, et existe depuis quelques générations maintenant, mais cette fois-ci, un DSP audio quad-core complet a été ajouté. Si vous voulez avoir toujours des micros qui peuvent ou non envoyer silencieusement des données à des personnes que vous ne voulez pas avoir, cette technologie le fera beaucoup mieux que la dernière génération. Yay?
Sur le front des E / S, il y a aussi des changements assez lourds avec 6 ports USB 3.1 et 10 USB 2.0 supportés. PCIe est toujours bloqué à la génération 3, mais il existe 16 voies utilisables avec 3x SATA6 et un port eMMC5.1. Notre gros problème ici est que si vous voulez un vrai GPU sur un système Ice, vous pouvez le faire mais vous ne pouvez pas non plus disposer d’un stockage rapide PCIe. Lequel est le plus important pour vous? AMD a fait beaucoup mieux pour les entrées / sorties symétriques. Sur un système Ryzen, vous n’avez pas à choisir la fonction obligatoire que vous souhaitez, utilisez le programme Intel.
Plus intéressant est l’intégration de Thunderbolt, quelque chose dont SemiAccurate vous a parlé pour la première fois en 2015, mais pour Cannon Lake. Une grande partie du dé est dédiée à Thunderbolt. Il s’agit également des blocs PCIe, TB ajoute simplement une petite surface au total. Intel réclame des économies d’énergie substantielles avec cette intégration, un pic de 300 mW. Mieux encore, ils peuvent désormais exécuter 8 voies PCIe overclockées à 20 Gbps au lieu de 17 voies de 8 Gbps pour les pièces externes de dernière génération. Si vous êtes minutieux, il y a maintenant quatre complexes racinaires, ce qui est plus que granulaire.
L'intégration de Thunderbolt est un moyen beaucoup plus efficace et efficace, mais personne chez Intel ne pose la question la plus évidente: "Pourquoi prenons-nous la peine de maintenir cette dinde en vie?". La réponse est que cela constituera la base de l’USB4, de sorte que d’autres devront s’y conformer, en supposant que cela ne tue pas complètement l’USB. Le temps nous le dira mais les choses ne semblent pas bouger dans ce sens.
Plus petit, plus petit:

Ce sont vraiment petits
Sur le plan de l'emballage, les choses deviennent très intéressantes. Ice possède des régulateurs de tension intégrés pour le CPU et le PCH, ainsi que de minces réseaux d’inductances magnétiques. Cela leur permet d’adapter Ice et PCH à des boîtiers multi-puces appelés Type3 (15W) et Type4 (9W). Le premier est de 10x25x1,3 mm avec 1526 balles sur un pas de .65mm tandis que le dernier est de 26,5 × 18,5x1mm et 1377 boules sur un pas de .43mm. Ces exploits sont impressionnants et peuvent même prendre en charge la mémoire x64 LPDDR4x sur la configuration PoP.
Sur le front du Wi-Fi, l’intégration du Wi-Fi 6, également appelé 802.11ax, est un peu mêlée. Les fonctions elles-mêmes ne sont pas un problème, c’est le connecteur CNVi 2 qui nous énerve. Pourquoi un lien vers la puce RF AX201 discrète nous dérangerait-il? Parce que le lien est propriétaire et que Intel ne le concède à personne, il ressemble donc à Intel Wi-Fi ou à plus d’argent.
En soi, ce n’est pas un problème non plus, mais associé au projet Athena, qui impose le Wi-Fi6, vous pourriez avoir des problèmes. Heureusement, il n'y a pas de jeux d'argent avec Athena, cette année. Attendez-le, mais n'attendez pas qu'Intel ouvre cette spécification. Ce genre de chose est ce qui a ruiné le marché des ordinateurs portables quand Intel a forcé ses concurrents à se démarquer du programme Ultrabook. Ils promettent à Athéna de ne pas le faire cette fois-ci, mais tout indique que l’histoire se répète.
Blessures auto-infligées:
En fin de compte, qu'avons-nous avec Ice Lake / Sunny Cove? Vous avez un noyau techniquement solide qui semble plus beau qu’à cause du blanchiment historique de Cannon Lake. Il est plus efficace que ses prédécesseurs mais, malheureusement, Intel n’y parvient pas. Le volume est à la limite inexistant, la performance est au mieux égale à celle de leurs prédécesseurs de 14 nm et les horloges, le nombre vendu aux consommateurs, sont en baisse de plus que l'IPC.
Pour les deux prochaines années, la majorité écrasante des ventes d’Intel sera encore au 14 nm. Pour les deux prochaines années, 14 milles aura toujours la couronne de performance. Pour les deux prochaines années, Intel ne sera pas en mesure de fabriquer des pièces de 10 nm de manière rentable. Intel ne publiera pas non plus la taille des puces ou le nombre de transistors, vous pouvez donc être sûr que 10 nm ne sera pas à la hauteur de leurs revendications. En bref, Intel s’est tiré une nouvelle fois dans le pied, ils ont conçu quelque chose qu’ils ne peuvent pas fabriquer mais qui ne cesse de prétendre que c’est génial. Ce n’est pas le cas, mais c’est beaucoup moins grave.S | A






Commentaires
Laisser un commentaire