Cluster à haute disponibilité – Wikipedia – Bien choisir son serveur d impression
Clusters à haute disponibilité (aussi connu sous le nom Grappes HA ou clusters de basculement) sont des groupes d’ordinateurs prenant en charge des applications serveur pouvant être utilisées de manière fiable avec un minimum de temps mort. Ils utilisent un logiciel à haute disponibilité pour exploiter les ordinateurs redondants en groupes ou en clusters offrant un service continu en cas de défaillance des composants du système. Sans la mise en cluster, si un serveur exécutant une application particulière tombe en panne, l'application sera indisponible jusqu'à ce que le serveur en panne soit réparé. La mise en cluster haute disponibilité corrige cette situation en détectant les défaillances matérielles / logicielles et en redémarrant immédiatement l'application sur un autre système sans intervention administrative, processus appelé basculement. Dans le cadre de ce processus, le logiciel de clustering peut configurer le nœud avant de lancer l'application sur celui-ci. Par exemple, il peut être nécessaire d'importer et de monter des systèmes de fichiers appropriés, de configurer le matériel réseau et d'exécuter également certaines applications prises en charge.[1]
Les clusters haute disponibilité sont souvent utilisés pour les bases de données critiques, le partage de fichiers sur un réseau, les applications métier et les services clients, tels que les sites Web de commerce électronique.
Les implémentations de cluster haute disponibilité tentent de créer une redondance dans un cluster afin d'éliminer les points de défaillance uniques, notamment les connexions réseau multiples et le stockage de données connecté de manière redondante via des réseaux de stockage.
Les clusters haute disponibilité utilisent généralement une connexion réseau privée Heartbeat qui permet de surveiller la santé et l'état de chaque nœud du cluster. Une condition subtile mais grave que tous les logiciels de clustering doivent pouvoir prendre en charge est la division du cerveau, ce qui se produit lorsque tous les liens privés sont désactivés simultanément, mais que les nœuds de cluster sont toujours en cours d'exécution. Si cela se produit, chaque nœud du cluster peut décider à tort que tous les autres nœuds sont tombés en panne et tenter de démarrer des services que d'autres nœuds sont toujours en cours d'exécution. La duplication d'instances de services peut entraîner une corruption des données sur le stockage partagé.
Les clusters HA utilisent également souvent le stockage témoin de quorum (local ou cloud) pour éviter ce scénario. Un dispositif témoin ne peut pas être partagé entre deux moitiés d'un cluster fractionné. Ainsi, dans le cas où tous les membres du cluster ne peuvent pas communiquer entre eux (par exemple, un battement de cœur ayant échoué), si un membre ne peut pas accéder au témoin, il ne peut pas devenir actif.
Sommaire
Exigences de conception de l'application[[[[modifier]
Toutes les applications ne peuvent pas fonctionner dans un environnement de cluster à haute disponibilité et les décisions de conception nécessaires doivent être prises tôt dans la phase de conception du logiciel. Pour fonctionner dans un environnement de cluster à haute disponibilité, une application doit satisfaire au moins les exigences techniques suivantes, dont les deux dernières sont essentielles à la fiabilité de son fonctionnement dans un cluster et sont les plus difficiles à satisfaire pleinement:
- Il doit exister un moyen relativement facile de démarrer, d’arrêter, d’arrêter de force et de vérifier le statut de l’application. Concrètement, cela signifie que l'application doit disposer d'une interface de ligne de commande ou de scripts pour la contrôler, y compris la prise en charge de plusieurs instances de l'application.
- L'application doit pouvoir utiliser le stockage partagé (NAS / SAN).
- Plus important encore, l'application doit stocker autant que possible son état sur un stockage partagé non volatile. La possibilité de redémarrer sur un autre nœud au dernier état avant une défaillance en utilisant l'état enregistré à partir du stockage partagé est tout aussi importante.
- L'application ne doit pas altérer les données si elle se bloque ou si elle est redémarrée à partir de l'état enregistré.
- Un certain nombre de ces contraintes peuvent être minimisées grâce à l'utilisation d'environnements de serveurs virtuels, dans lesquels l'hyperviseur est lui-même sensible aux clusters et permet la migration transparente des machines virtuelles (y compris l'état de la mémoire en cours d'exécution) entre des hôtes physiques – voir Clusters de basculement Microsoft Server 2012 et 2016 .
- Une différence essentielle entre cette approche et l’exécution d’applications axées sur les clusters réside dans le fait que ces dernières peuvent gérer les pannes d’applications de serveur et prendre en charge les mises à niveau logicielles "continues" tout en maintenant l’accès client au service (par exemple, la base de données), en faisant en sorte qu’une instance fournisse le service est mis à niveau ou réparé. Cela nécessite que les instances de cluster communiquent, vident les caches et coordonnent l'accès aux fichiers lors du transfert.
Configurations de nœuds[[[[modifier]

La taille la plus courante pour un cluster haute disponibilité est un cluster à deux nœuds, car il s'agit du minimum requis pour assurer la redondance, mais de nombreux clusters se composent de plusieurs autres, parfois des dizaines de nœuds.
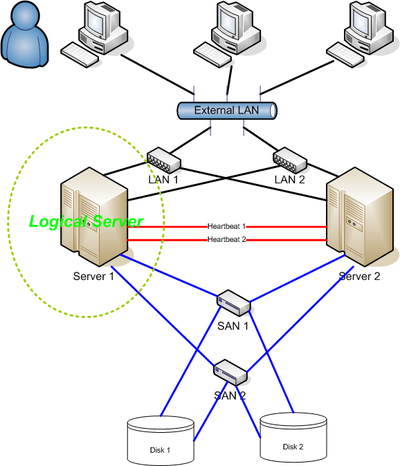
Le diagramme ci-joint donne une bonne vue d'ensemble d'un cluster de haute disponibilité classique, en précisant qu'il ne fait aucune mention de la fonctionnalité de quorum / témoin (voir ci-dessus).
De telles configurations peuvent parfois être classées dans l'un des modèles suivants:
- Actif / actif – Le trafic destiné au nœud défaillant est transféré sur un nœud existant ou équilibré entre les nœuds restants. Cela n'est généralement possible que lorsque les nœuds utilisent une configuration logicielle homogène.
- Actif / passif – Fournit une instance entièrement redondante de chaque nœud, qui est mise en ligne uniquement en cas de défaillance du nœud principal associé.[2] Cette configuration nécessite généralement le matériel le plus supplémentaire.
- N + 1 – Fournit un seul nœud supplémentaire mis en ligne pour prendre en charge le rôle du nœud en panne. Dans le cas d'une configuration logicielle hétérogène sur chaque nœud principal, le nœud supplémentaire doit être universellement capable d'assumer n'importe quel rôle des nœuds principaux dont il est responsable. Cela concerne normalement les clusters ayant plusieurs services exécutés simultanément; dans le cas d'un service unique, cela dégénère en actif / passif.
- N + M – Dans les cas où un seul cluster gère plusieurs services, le fait d'avoir un seul nœud de basculement dédié peut ne pas offrir une redondance suffisante. Dans ce cas, plus d'un (M) serveur de secours est inclus et disponible. Le nombre de serveurs en attente est un compromis entre les exigences de coût et de fiabilité.
- N-to-1 – Permet au nœud de secours de basculement de devenir temporairement actif, jusqu'à ce que le nœud d'origine puisse être restauré ou remis en ligne. A ce stade, les services ou les instances doivent y être restaurés afin de restaurer la haute disponibilité. .
- N-to-N – Combinaison de clusters actifs / actifs et N + M, les clusters N à N redistribuent les services, instances ou connexions du noeud en panne parmi les noeuds actifs restants, éliminant ainsi le besoin (comme avec actif / actif). pour un nœud «en attente», mais en introduisant un besoin de capacité supplémentaire sur tous les nœuds actifs.
Les termes hôte logique ou cluster hôte logique est utilisé pour décrire l'adresse réseau utilisée pour accéder aux services fournis par le cluster. Cette identité d'hôte logique n'est pas liée à un seul nœud de cluster. Il s'agit en réalité d'une adresse réseau / d'un nom d'hôte lié au (x) service (s) fourni (s) par le cluster. Si un nœud de cluster avec une base de données en cours d'exécution tombe en panne, la base de données sera redémarrée sur un autre nœud de cluster.
Fiabilité des nœuds[[[[modifier]
Les clusters HA utilisent généralement toutes les techniques disponibles pour rendre les systèmes individuels et l'infrastructure partagée aussi fiables que possible. Ceux-ci inclus:
- Mise en miroir de disques (ou tableaux redondants de disques indépendants –RAID) afin que la défaillance des disques internes n'entraîne pas de panne du système. Le périphérique de bloc répliqué distribué est un exemple.
- Connexions réseau redondantes afin que les défaillances de câbles, commutateurs ou interfaces réseau uniques n'entraînent pas de pannes réseau.
- Connexions au réseau de stockage (SAN) redondantes, de sorte que les défaillances de câbles, de commutateurs ou d'interfaces uniques n'entraînent pas de perte de connectivité au stockage (cela violerait l'architecture sans partage).
- Les entrées d'alimentation électrique redondantes sur différents circuits, généralement protégées toutes les deux par des unités d'alimentation sans coupure, ainsi que les unités d'alimentation redondantes, de manière à ce qu'une alimentation simple, un câble, un UPS ou une panne d'alimentation n'entraîne pas une perte d'alimentation du système.
Ces fonctionnalités permettent de minimiser les risques de basculement en cluster entre systèmes. Dans un tel basculement, le service fourni est indisponible pendant au moins un certain temps. Par conséquent, les mesures permettant d'éviter le basculement sont préférées.
Stratégies de basculement[[[[modifier]
Les systèmes qui gèrent les pannes dans l'informatique distribuée ont différentes stratégies pour y remédier. Par exemple, l’API Hache d’Apache Cassandra définit trois manières de configurer un basculement:
- Fail Fast, scripté comme "FAIL_FAST", signifie que la tentative de remédier à l'échec échoue si le premier noeud ne peut pas être atteint.
- En cas d'échec, essayez-en – Suivant disponible, scripté "ON_FAIL_TRY_ONE_NEXT_AVAILABLE", signifie que le système essaie un hôte, le plus accessible ou le plus disponible, avant d'abandonner.
- En cas d'échec, essayez tous, scripté comme "ON_FAIL_TRY_ALL_AVAILABLE", signifie que le système essaie tous les nœuds existants et disponibles avant d'abandonner.
Implémentations[[[[modifier]
Plusieurs solutions gratuites et commerciales sont disponibles, telles que:
Voir également[[[[modifier]
Références[[[[modifier]
Lectures complémentaires[[[[modifier]
- Greg Pfister: À la recherche de grappes, Prentice Hall, ISBN 0-13-899709-8
- Evan Marcus, Hal Stern: Plans de haute disponibilité: conception de systèmes distribués résilients, John Wiley & Sons, ISBN 0-471-35601-8
- Chee-Wei Ang, Chen-Khong Tham: Analyse et optimisation de la disponibilité du service dans un cluster haute disponibilité avec disponibilité de la machine en fonction de la charge, Transactions IEEE sur les systèmes parallèles et distribués, volume 18, publication 9 (septembre 2007), pages 1307-1319, ISSN 1045-9219 [1]






Commentaires
Laisser un commentaire