
L'importance de Python dans l'administration de SQL Server – Serveur d’impression
Certains de mes articles précédents sur Python donnaient un aperçu des bases et de l'utilisation de Python dans SQL Server 2017.
Cet article vise à rassembler toutes les pièces manquantes et à démontrer l’importance de l’utilisation de la programmation Python dans SQL Server.
Beaucoup disent que PowerShell a l'avantage sur Python dans certains aspects de l'administration de la base de données. Moi aussi, je ressens la même impression que de nombreux passionnés de technique, mais avec une connaissance très limitée, nous pouvons également voir le pouvoir de Python. Peut-être, au lieu de comparer PowerShell et Python, nous pouvons les considérer comme des technologies complémentaires.
En 2016, R, le langage de programmation informatique statistique a été intégré à la version de SQL Server, nommée pour la même année. L’autre côté de la médaille était absent, car Python est également un langage de premier plan pour l’apprentissage automatique et compte même un grand nombre d’utilisateurs. Dans SQL Server 2017, Python est intégré. Maintenant, R et Python sont sous le même parapluie de la fonctionnalité appelée services d'apprentissage automatique.
Comme Python est un langage de programmation commun adopté par les scientifiques de données et les administrateurs de base de données, la possibilité d’exécuter du code Python en tant que script T-SQL permet aux fonctions d’apprentissage automatique de traiter directement de grandes quantités de données. Premièrement, il n'est plus nécessaire d'extraire des données de la base de données avant de pouvoir les traiter via un programme client. Cela nous offre des avantages importants en termes de sécurité, d'intégrité et de conformité, qui surviennent lorsque des données sont par ailleurs déplacées en dehors de l'environnement hautement contrôlé dans le moteur de base de données. De plus, les calculs sont effectués sur le serveur lui-même sans avoir à transférer les données à un client, ce qui impose une charge importante sur le trafic réseau. Cela signifie également que vous pouvez effectuer des calculs sur l'intégralité du jeu de données sans avoir à prélever des échantillons représentatifs, ce qui est courant lors du traitement de données sur une machine distincte. Et comme les données restent en place, vous pouvez tirer pleinement parti des avantages en termes de performances apportés par les technologies SQL Server telles que les tables en mémoire et les index de magasin de colonnes. Le code Python est également très facile à déployer et peut être écrit directement dans une commande Transact-SQL.
Ensuite, SQL Server 2017 prend en charge l'installation de tous les packages Python dont nous pourrions avoir besoin afin que vous puissiez vous appuyer sur la vaste collection de fonctionnalités Open Source développées par la communauté Python plus large. Enfin, l'intégration Python est disponible dans toutes les éditions de SQL Server 2017, y compris l'édition Express gratuite. Ainsi, quelle que soit l'ampleur de votre application, vous pouvez tirer parti de l'intégration Python.
Pour vous aider à démarrer, SQL Server 2017 inclut un certain nombre de bibliothèques d'Anaconda, une plate-forme de science de données très populaire. De plus, Microsoft a créé deux bibliothèques installées avec Machine Learning Services.
- Revoscalepy
Revoscalepy est une bibliothèque de fonctions prenant en charge l'informatique distribuée, les contextes de calcul à distance et les algorithmes hautes performances.
- Microsoftml
La bibliothèque Microsoftml contient des fonctions pour les algorithmes d’apprentissage automatique, notamment la création de modèles linéaires, d’arbres de décision, de régression logistique, de réseaux de neurones et de détection d’anomalies.
Sommaire
Commençons
Les méthodes d'analyse traditionnelles au sein de SQL Server utilisant divers composants Microsoft tels que SQL, MDX, DAX dans PowerPivot offrent la flexibilité nécessaire pour transformer des données. Désormais, le langage R, un autre riche ensemble de modules d'apprentissage automatique pour l'analyse de données, est directement intégré à SQL Server 2016. R est un autre langage qui possède une base d'utilisateurs importante, avec Python. Avec les modules disponibles en Python, l'analyse des données devient plus efficace.
Permettez-moi de vous donner quelques exemples pour prouver que l'utilisation de Python dans SQL Server est un moyen efficace d'extraire des données de serveurs distants.
-
Voir comment se connecter à une source de données SQL Server à l'aide de pyodbc
-
Exécutez la requête SQL, dans ce cas, créez la chaîne de connexion qui pointe vers une instance SQL distante et exécutez la requête Dynamic Management View sys.dm_os_waitstas.
-
Attribuer la sortie SQL aux trames de données
-
Afficher les 10 premières lignes du jeu de résultats SQL à l'aide de la fonction head
La commande head permet d’afficher les premières «n» lignes du cadre de données. Cela ressemble à la commande supérieure de SQL Server. La première colonne (montrant 0 à 9) est l'index par défaut pour le cadre de données -
Afin de convertir les données du cadre de données en colonnes SQL associées, la clause WITH RESULTS SET est définie à la fin du code. Cela nous donne la possibilité de définir la colonne et les types associés de chaque colonne.
-
WITH RESULT SETS requiert que le nombre de colonnes de la définition de résultat soit égal au nombre de colonnes renvoyées par la procédure stockée / requête SQL. Dans les exemples suivants, la sortie de la requête SQL renvoie quatre colonnes: nom_serveur, type_attente, nombre_attentes_attente, nombre_attendus. Celles-ci correspondent à la définition de la clause with result sets.
|
EXEC sp_execute_external_script @la langue = N'python', @scénario = N'importer pyodbc importer des pandas en tant que pd connexion = pyodbc.connect (''DRIVER = Pilote ODBC 13 pour SQL Server; SERVEUR = hqdbsp18; UID = sa; PWD = api1401'') curseur = connexion.curseur () requête = ''SELECT wait_type, waiting_tasks_count, wait_time_ms FROM sys.dm_os_wait_stats'' df = pd.read_sql (requête, connexion) print (df.head (5)) connection.close () ' |
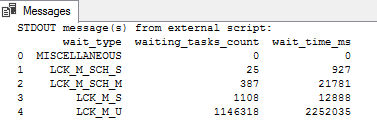
La sortie de requête SQL ci-dessus peut également être renvoyée sous forme de table SQL à l'aide de avec clause de résultat.
|
EXEC sp_execute_external_script @la langue = N'python', @scénario = N'importer pyodbc importer des pandas comme pa connexion = pyodbc.connect (''DRIVER = Pilote ODBC 13 pour SQL Server; SERVEUR = hqdbsp18; UID = sa; PWD = sqlshackai1401'') requête = ''SELECT @@ nom_serveur, type_attend, nombre_attentes_attente, nombre_attendus FROM sys.dm_os_wait_stats'' pa.read_sql (requête, connexion) OutputDataSet = pa.read_sql (requête, connexion) ' AVEC RÉSULTAT SETS((nom du serveur varchar(20),waiting_Type varchar(256), waiting_tasks_count bigint, wait_time_ms décimal(20,5))) |
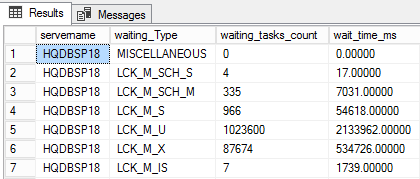
Examinons un exemple pour insérer les exemples de données dans le tableau. L'exemple de requête SQL suivant fournit les informations internes à la base de données, imprimées sous forme de sortie chaîne.
|
1 2 3 4 5 6 7 8 9 dix 11 12 13 14 15 16 17 18 19 20 21 22 |
EXEC sp_execute_external_script @la langue = N'Python' , @scénario = N'importer pyodbc importer des pandas comme pa avec open ("f: PowerSQL server.txt", "r") comme infile: lines = infile.read (). splitlines () pour ligne en ligne: serveur = ligne serveur d'imprimante) database = "Master" cnxn = pyodbc.connect ("DRIVER = pilote ODBC 13 pour SQL Server; SERVEUR =" + serveur + "; PORT = 1443; DATABASE =" + base de données + "; UID = sa; PWD = api1401") tsql = "" " SÉLECTIONNER @@ SERVERNAME nom_serveur, CONVERT (VARCHAR (25), DB.name) AS DatabaseName, (SELECT nombre (1) FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid! = 0) AS [DataFiles], (SELECT cast (SUM ((taille * 8) / 1024) sous forme décimale (10,2)) FROM FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid! = 0) AS [DataMB], (SELECT count (1) FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid = 0) AS [LogMB], (SELECT cast (SUM ((taille * 8) / 1024) sous forme décimale (10,2)) FROM FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid = 0) AS [LogMB] FROM sys.databases DB ORDER BY DatabaseName "" " print (pa.read_sql (tsql, cnxn)) ' |
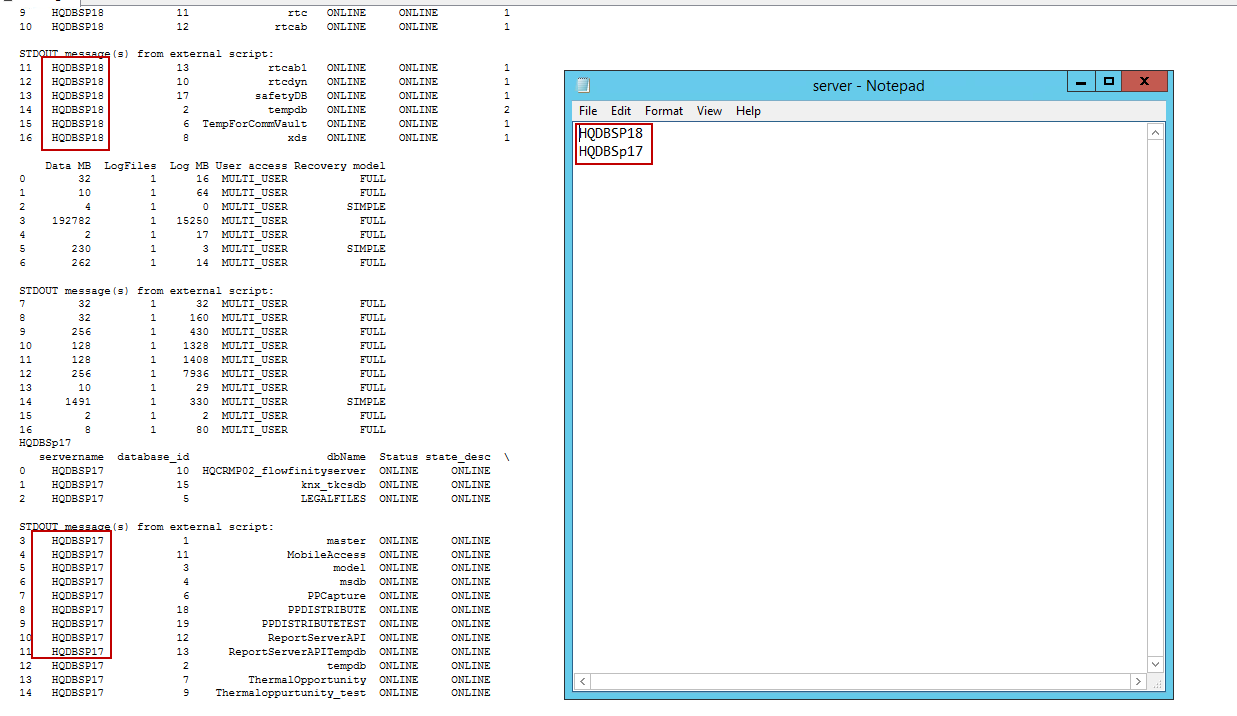
Le code SQL suivant crée une table de démonstration sur l'instance cible. SQLShackDemoDB est le nom de la base de données cible.
|
UTILISATION [[[[SQLShackDemoDB] ALLER CRÉER TABLE [[[[dbo].[[[[tbl_databaseInventory]( [[[[Nom du serveur] [[[[varchar](100) NE PAS NUL, [[[[nom de la base de données] [[[[varchar](25) NUL, [[[[Fichiers de données] [[[[int] NUL, [[[[DataMB] [[[[int] NUL, [[[[LogFiles] [[[[int] NUL, [[[[LogMB] [[[[int] NUL ) SUR [[[[PRIMAIRE] ALLER |
La procédure stockée nommée P_SampleDBInventory_Python est créé avec deux connexions.
-
Charger le pyodbc Module Python pour la connectivité de données
-
Construisez la chaîne de connexion cible. Il inclut les détails de l'objet de destination tels que l'instance cible, la base de données et la table.
-
Ouvre le curseur
-
La deuxième chaîne de connexion est construite à l'aide d'un fichier. Le fichier est la source des noms de serveur d'entrée. La requête doit traverser les listes pour générer les ensembles de données. Ensuite, l'ensemble de données est parcouru pour extraire les détails de la colonne dans la destination à l'aide de la chaîne de connexion cible
-
Générez l'instruction SQL à l'aide de guillemets triples. Les triples guillemets sont utilisés pour créer des chaînes régulières pouvant s'étendre sur plusieurs lignes.
-
L'instruction SQL est exécutée à l'aide du curseur défini
-
Les résultats sont chargés dans la table de destination
-
Appeler la procédure stockée
EXEC P_SampleDBInventory_Python
-
Vérifier la sortie SQL
Pour la chaîne de connexion cible,
|
1 2 3 4 5 6 7 8 9 dix 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
CRÉER Procédure P_SampleDBInventory_Python COMME EXEC sp_execute_external_script @la langue = N'Python' , @scénario = N' importer pyodbc importer des pandas comme pa Instance = ''HQBT01'' Base de données = ''SQLShackDemoDB'' uname = ''thanVitha2017'' pwd = ''thanVitha2017401 $'' conn1 = pyodbc.connect (''DRIVER = Pilote ODBC 13 pour SQL Server; SERVER =''+ Instance +''; PORT = 1443; DATABASE =''+ Database +''; UID =''+ uname +''; PWD =''+ pwd) cur1 = conn1.cursor () avec open ("f: PowerSQL server.txt", "r") comme infile: Entrée = infile.read (). Splitlines () pour l'entrée en entrée: srv = sInput print (srv) db = "master" conn2 = pyodbc.connect ("DRIVER = pilote ODBC 13 pour SQL Server; SERVEUR =" + srv + "; PORT = 1443; DATABASE =" + db + "; UID = sa; PWD = as21201") cur2 = conn2.cursor () SQL1 = "" " SÉLECTIONNER @@ SERVERNAME nom_serveur, CONVERT (VARCHAR (25), DB.name) AS DatabaseName, (SELECT nombre (1) FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid! = 0) AS [DataFiles], (SELECT cast (SUM ((taille * 8) / 1024) sous forme décimale (10,2)) FROM FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid! = 0) AS [DataMB], (SELECT count (1) FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid = 0) AS [LogFiles], (SELECT cast (SUM ((taille * 8) / 1024) sous forme décimale (10,2)) FROM FROM sysaltfiles WHERE DB_NAME (dbid) = DB.name AND groupid = 0) AS [LogMB] FROM sys.databases DB ORDER BY DatabaseName; "" " avec cur2.execute (SQL1): rangée = curseur.fetchone () en rangée: print (str (row)[0]) + "" + Str (rangée[1]) + "" + Str (rangée[2]) + "" + Str (rangée[3]) + "" + Str (rangée[4]) + "" + Str (rangée[5])) SQL2 = "INSERT INTO [tbl_DatabaseInventory] (Nom du serveur, Nom de la base de données, DataFiles, DataMB, LogFiles, LogMB) VALEURS (?,?,?,?,?,?); " avec cur1.execute (SQL2, str (ligne[0]), str (rangée[1]),rangée[2],rangée[3],rangée[4],rangée[5]): impression (''Inséré avec succès!'') rangée = curseur.fetchone () ' FIN |
Sortie:
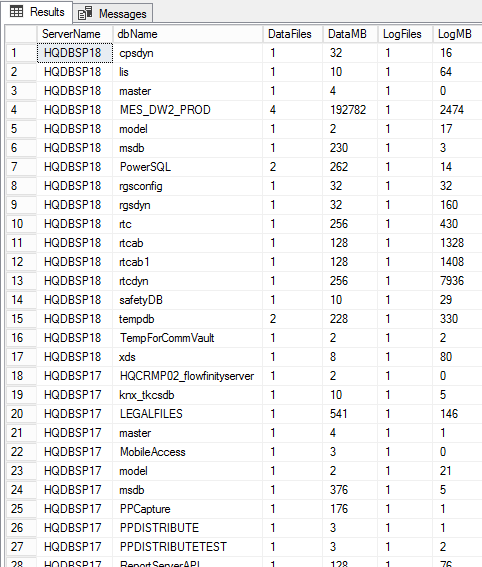
Emballer
Donc là vous l'avez. Bien que les exemples fournis soient assez simples, j'espère que vous pourrez voir à quel point Python pourrait être utile pour un administrateur de base de données également, et pas seulement pour un spécialiste en informatique ou en données.
La vraie beauté est que tout ce code pourrait s'asseoir dans une procédure stockée; quelque chose que vous ne pouvez pas tout faire aussi bien avec PowerShell.
L'intégration de Python dans SQL Server 2017 offre aux chercheurs en données un moyen simple d'interagir avec leurs données directement dans le moteur de base de données, ainsi qu'aux développeurs un moyen simple d'intégrer des modèles Python à leur application via de simples procédures stockées.

Prashanth Jayaram
Ma spécialité réside dans la conception et la mise en œuvre de solutions de haute disponibilité et de migration multi-plateformes de bases de données. Les technologies actuellement utilisées sont SQL Server, PowerShell, Oracle et MongoDB.
Voir tous les messages de Prashanth Jayaram






Commentaires
Laisser un commentaire